
Vol 4 (2021), No 2: 14–51
DOI: 10.21248/jfml.2021.30
Discussion paper available at:
(Re-)Opening an encounter in the virtual world of Second Life
On types of joint presence in avatar interaction
Abstract
This study explores how ‘gatherings’ turn into ‘encounters’ in a virtual world (VW) context. Most communication technologies enable only focused encounters between distributed participants, but in VWs both gatherings and encounters can occur. We present close sequential analysis of moments when after a silent gathering, interaction among participants in a VW is gradually resumed, and also investigate the social actions in the verbal (re-)opening turns. Our findings show that like in face-to-face situations, also in VWs participants often use different types of embodied resources to achieve the transition, rather than rely on verbal means only. However, the transition process in VWs has distinctive characteristics compared to the one in face-to-face situations. We discuss how participants in a VW use virtually embodied pre-beginnings to display what we call encounter-readiness, instead of displaying lack of presence by avatar stillness. The data comprise 40 episodes of video-recorded team interactions in a VW.
Keywords: avatars, conversation analysis, co-presence, encounter, gathering, multimodal interaction, (re-)openings, participation, transition, virtual embodiment, virtual worlds
1 Introduction
Goffman (1963) suggests that there are two principal ways in which social situations are organized, that is, how people are present with someone in a shared space. The division between ‘encounters’ and ‘gatherings’ − the two types of joint presence − is made on the basis of the behavioral obligations that pertain the given situation. In both situations, individuals are physically close enough to perceive others and to sense to be similarly perceived by them. In gatherings, such as when strangers pass by one another on the street, the individuals do not have a joint focus of attention and are not engaged in being in focused interaction with others (Goffman 1963: 17, 88). In an encounter, on the contrary, the participants share a joint orientation by, for instance, having a conversation, which makes their interaction ‘focused’.
In computer-mediated communication, which is under consideration in the present study, the division between gatherings and encounters is an intriguing study area given that the possibility for an unfocused gathering does not easily exist: communication technologies are primarily developed for connecting people for having focused interaction across distances (see, however, Heath/Luff 1992 and Luff et al. 2003 on ‘media spaces’). Especially because of the lack of joint, surrounding space where distributed individuals could just be co-present with one another using virtual bodies but without having interactional obligations, situations of unfocused gatherings rarely emerge. For example, in video calls, people rarely just ‘hang around’ like they do in coffee houses or libraries, for instance. Instead, they are usually engaged in a focused encounter with one another during the entire time the mutual connection is open. Differentiating between a gathering and an encounter in computer-mediated communication is difficult also because of the lack of eye contact, subtle body movements and orientation to joint objects and surroundings, which in face-to-face settings are exploited as interactional devices and cues for differentiating gatherings and encounters and for transitioning from one to the other (Mondada 2009; De Stefani/Mondada 2018).
Both gatherings and encounters are, however, possible in computer-mediated communication as well, when three-dimensional virtual world (VW) technology is used (see also Heath/Luff 1992 and Luff et al. 2003 for other technologies developed for computer-supported cooperative work). When compared to other communication technologies, VWs make mediated interactions more similar to face-to-face situations by the use of virtual embodiment, that is, avatar characters inside a joint space, and hence both gatherings and encounters may occur (Moore et al. 2006). However, the difference between a virtual gathering and a virtual encounter as well as the details of the interactional processes in transitioning between the two require further investigation. Mondada (2009) has investigated the transition process in face-to-face situations: between strangers passing each other on the street. However, for example due to the lack of eye contact between avatars, it is expected that this process is significantly different in VWs.
One way to approach gatherings and encounters in a VW context is to relate them to the concept of presence, and more specifically, to the two types of joint presence: co-presence and social presence. Co-presence in a VW is mostly understood as the feeling of not being alone and as the awareness of other users in the joint space (i.e., being in a ‘gathering’). Social presence, on the other hand, refers to being with others in a joint virtual space but also experiencing psychological involvement and behavioral engagement with them (i.e., being in an ‘encounter’; Biocca et al. 2003). Despite the vast body of research on social presence in VWs (e.g., Mennecke et al. 2011; Schultze/Brooks 2019), relatively little is known about the detailed interactional process of achieving social presence − that is, an ‘encounter’ − between the co-present individuals. In the field of computer-mediated communication, one reason for this lack of understanding may be in the tradition of treating social presence mainly as a product of the mind (see, e.g., Lombard/Ditton 1997), leaving the related interactional practices for a lesser attention (Kohonen-Aho/Alin 2015; Sivunen/Nordbäck 2015).
As a distinction to the existing research on social presence in VWs, we propose that this concept should be investigated not merely as an individual’s perception of others but rather as something that is observable and negotiated in interaction − as is done in the fields of interactional linguistics and conversation analysis, for instance (see, e.g., Mondada 2009). Being present and indicating presence are thus understood and investigated as phenomena that involve not only language but also − and perhaps more importantly − bodily cues. In addition, from the conversation analytic perspective, it is difficult to assess how the individuals experience psychological involvement with others, which is the defining criterion for the concept of social presence: mental processes are not easily observable in social interaction and thus they are difficult to prove with evidence from data. This is why we prefer utilizing the Goffmanian terminology in our study.
In the present study, we investigate how the VW gatherings turn into encounters in the VW of Second Life. We analyze 40 transition episodes in 12 video-recorded virtual team collaboration sessions during which silent gatherings were followed by focused encounters. The members in each team were situated in separate rooms and they had access to their team mates only in the VW and through an audio connection. We video-recorded each team member both in the VW and in their physical locations.
We apply the analytic practices of multimodal conversation analysis (Goodwin 2000; Mondada 2016) to capture the simultaneous occurrence of talk and bodily action as they unfold moment by moment. Our findings suggest that there are two main processes used to transition from a gathering to an encounter: one where virtually embodied behavior functions as a pre-beginning to the encounter, and one where it is not used. Additionally, we examine how the VW encounters are opened - which, interestingly, always happens verbally in our data, as the avatars’ embodied behavior alone does not seem to constitute social interaction between the participants. We thus also examine the participants’ first verbal turns after a silence. Since the gathering-encounter transitions occur multiple times in each team, we call the verbal turns as re-openings.
Based on our findings, we discuss the role of virtually embodied pre-beginnings in indicating what we call “encounter-readiness” with co-participants in a VW. Our study also contributes to the research on (re-)openings of interactions from a conversation analytic perspective by concentrating on multimodal practices in openings in a specific technology-mediated setting. It also provides insight into (social) presence as a behaviorally displayed entity in VWs.
2 Background
2.1 Transitions between types of situations and activities
The significance of what happens prior to actual interaction has been found out already early on in conversation analytic literature. These ‘pre-beginnings’ are considered as phases of incipient interaction that determine the way in which the situation continues (e.g., Schegloff 1979); among the main components are the identification and recognition of other(s). Later studies have pointed out that a ‘pre’-phase is essential for different transitions in general. We will now review the studies that are most relevant for the present article.
When co-present individuals are in a gathering, they can any time transform the situation into a mutual encounter. This transition usually occurs when one participant initiates a conversation, or when mutual attention is created nonverbally such as by establishing eye contact, using gestures to get the other’s attention, or signaling an intent for an encounter with one’s body orientation (Goffman 1963: 33–37, 88–89). Mondada (2009) examined the establishment of an interactional space between individuals in a public place. According to her study, multimodal practices such as gaze and body orientation have an essential role in this transition before the first verbal turn is uttered. The studied setting included strangers passing one another on a street, and one of them opening an encounter to ask for directions. The focus was on what happened before the first verbal turn and on how the individuals spatially organized themselves and the forthcoming encounter.
According to Mondada (2009), the formation of an interactional space involves a three-step process (see Figure 1). When persons approach one another on a street, the situation is a gathering. Then one participant starts to engage in what Mondada calls a pre-opening, or an “embodied pre-beginning.” During this phase, the future co-participants gradually engage in mutual identification and recognition using multimodal resources that can be divided in three steps. First, the initiator uses gaze, glancing to identify and orient to a possible future co-participant and to secure his/her recipiency. Second, after the first glances, the participants gradually adjust their body movements and slow down their walking. Finally, they both slowly stop moving and stabilize the participation framework with their body postures. Only after this embodied pre-beginning, the first verbal turn takes place. These pre-conditions for an encounter “are visibly and publicly assembled in time, within the progressive establishment of a mutual focus of attention and a common interactional space” (Mondada 2009: 1977; on the initiation of institutional encounters, see Mortensen/Hazel 2014).
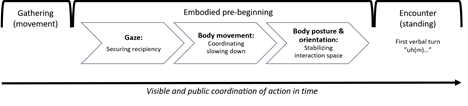
Figure 1: Transitioning from a gathering to an encounter (adapted from Mondada 2009).
In their recent study, De Stefani and Mondada (2018) examined how both strangers and acquainted persons entered into casual encounters in public spaces. What mainly differentiated strangers and acquainted persons in encounters was their joint history or the lack thereof, which leads to either the identification of an unknown person or the recognition of a familiar person as the potential interaction partner.
Transitions from a gathering to an encounter may also occur when the participants have already been involved in an encounter but the continuous conversation has then lapsed. Studies have identified a phenomenon often referred to as the ‘continuing state of incipient talk’, where co-present individuals engage in talk only sporadically, for example “members of a household in their living room, employees who share an office, passengers together in an automobile” (Schegloff/Sacks 1973: 324-325; see also Goffman 1963; Szymanski et al. 2006; Berger et al. 2016). These studies have, among other issues, looked at ways of resuming interaction after the periods of non-talk (i.e., how to “re-open” conversation; see Bergmann 1990; Szymanski 1999; Keevallik 2018). According to Hoey (2018), participants have three basic alternatives as to how to continue after a lapse – that is, after a silent moment between sequences of talk: they may move to end the interaction, continue with prior talk, or start something new. The participants practically achieve this transition from silence to talk not only by simply saying something, but subtle embodied behaviors are often exploited as well (Vatanen 2018; 2020). In the current study, however, the focal activity that precedes the imminent transitions is not talking but engaging in an individual activity, and hence the silent gatherings cannot directly be described as lapses (even though they involve no talk). Rather, what is more at stake is a transition between two different activities.
Previous research has found that when participants have a clearly available common activity at hand, they frequently transition between talking and being engaged in that activity. The local devices for achieving such transitions have been described for activities such as students doing group work in classrooms (Szymanski 1999), friends playing video games (Mondada 2012), and families engaged in foraging activities (Keisanen et al. 2017). Displaying availability for interaction is crucially related not only to the participants’ speech but also to their embodied behavior: certain body movements as well as gaze behavior function to elicit speech from the co-participant (Heath 1984). Directions and movements of the body and its parts are used to display participants’ involvement in different activities and participation frameworks (Goffman 1981; Goodwin 1984; Schegloff 1998; Kamunen 2019). The participants’ bodies in the given material environment create specific “contextual configurations”, which frame and constitute the participants’ actions (Goodwin 2000). The interactional space is created flexibly by arranging the participants’ bodies in relation to the ongoing activity and the local environment – for instance, in situations where participants transition from one activity to another (Mondada 2013). The participants’ body movements and spatial configurations are essential in making a transition from one activity to the next, for instance, when (trans-)forming the participation framework of a group of people (Broth/Keevallik 2014; Råman 2018).
Analyzing the participants’ embodied behavior during phases when they (possibly) transition from one activity to the next is crucial also in the present study. We are especially interested in how a participant makes oneself available for interaction and how they then jointly achieve the transition. That is, we investigate the ways in which individuals show their availability for interaction in a VW. Previous literature on interactions in VWs will be reviewed next.
2.2 Gatherings and encounters in a virtual world
VWs such as Second Life are persistent three-dimensional online environments developed for social interaction (Schroeder 2008). Second Life, for example, includes various types of spaces and places where users can spend time and interact. VWs include several channels for interaction, such as text-based communication in open and private chats and within virtual artifacts (e.g., virtual whiteboards), audio connection, and above all, a customizable avatar character capable of movements (e.g., walking, jumping, flying) and gestures (e.g., waving, smiling, nodding). Avatar as a virtual body provides users a sense of presence in a virtual space, co-existence with others, and interaction with other avatars and virtual objects.
The shared space as well as the virtually embodied co-presence using avatars are unique features of VWs in comparison with other communication technologies where participants do not usually share a joint location with bodily representations. Thus, unlike other communication technologies, VWs provide for the possibility for spatially oriented interaction (Benford/Fahlen 1993), and, importantly, the possibility for both gatherings and encounters to occur. In general, communication technologies are not designed for unfocused gatherings where people often have at least peripheral (unconscious) social awareness of the co-present others (Goffman 1963: 83). An exception is the ‘media space’ used in remote workplace interaction, discussed by Heath and Luff (1992), which allows both gatherings and encounters to occur but, because of the lack of joint space, does not support the use of subtle embodied cues when transitioning from one to the other.
In a VW, embodied users are virtually co-present in a shared space, which makes them continuously visible to one another, conveying the presence and location of the user in the virtual environment with cues about its body position as well (Schultze 2010). Thus, a shared space in VWs supports the process of seeing out of the corner of one's eye as well as glancing and overhearing, which are helpful for managing and coordinating one’s own activities as well as for predicting the activities of others in the shared space (Benford/Fahlen 1993).
Previous research has also attended to some gathering-like situations in VWs. For example, Bennerstedt and Ivarsson (2010) observed that between different phases in online games, players engage in “waiting activities” such as jumping with their avatars. Jumping in the presence of other players was not intended as focused interaction but rather as a signal to others that the player was still active in the game while waiting. Online games commonly include “idle animations” as well, which are different kinds of little activities that the avatars can do when a player wishes not to be interrupted or leaves the game for a while. By using an idle animation such as reading a book with one’s avatar, the player can remain in the presence of others in an unfocused manner. These types of behaviors are reminiscent of what has been shown to occur also in real-life situations when people wait. Waiting does not mean just standing still and/or doing nothing; instead, specific embodied resources are systematically employed to signal to other participants that waiting is taking place (Svinhufvud 2018; Ayaß 2020). Waiting can thus quite often be characterized as a type of a gathering.
The division between a gathering and an encounter in VWs relates to the research area of co-presence and social presence, as mentioned above. Mennecke et al. (2011) introduced the theory of embodied social presence in virtual worlds. According to this theory, being in a VW and using its contents easily evoke the sense of presence in the virtual space, eventually leading to the sense of co-presence (a gathering), followed by the sense of social presence (an encounter) with other users. However, this theory does not discuss the details on when, how and why the users engage in using the VW contents and avatars for achieving social presence, and the detailed process of transitioning from co-presence to social presence has not been properly attended to. As seen above, previous research has given hints about the significance of spatially defined interactions as well as the use of avatars, but the detailed practices the users engage in to signal availability as well as to (re-)open an encounter after being in a gathering are not yet properly understood − a research gap that we in the current paper aim to fill.
Another reason why the transition process itself has not gained much attention might lie in the difficulty of detecting the subtle interactional transition cues that people use in face-to-face situations in the context of VWs. Despite the increasing visual realism of VWs and the abilities of avatars to convey various types of social information, the users’ ongoing activities are still far less obvious for others to detect than they are in the physical reality. In face-to-face situations, participants use detailed observational (verbal and nonverbal) information when monitoring others in order to interpret their actions and to design appropriate responses to them. Accountability, projectability, and coordination of action crucially depend on this observational information, which include the unfolding of turn taking in real time and the observability of gaze and other embodied activities − features that are still under development in VWs. Especially since avatars do not unintendedly “give off” cues (Goffman 1959: 2) about their users’ activities as human bodies do, information about ongoing activities in VWs needs to be explicitly communicated (Moore et al. 2006). Otherwise, the avatars just stand still and do nothing, possibly giving a false sense of availability.
Even though avatars are less accountable for their actions than human bodies are, we suggest that since VWs enable the existence of both gatherings and encounters, the transition process between the two can be investigated − even though it may be less sophisticated than in face-to-face situations (see Mondada 2009). This is what we attempt to do in the remainder of this paper.
3 Empirical study
3.1 Participants and the interaction setting
The research data are collected from a setting where 12 virtual teams collaborated in Second Life. The participants (N=36) in this study were recruited among students from two universities in Finland as well as among friends and colleagues, and they were randomly divided into three-member teams. The members in each team were situated in separate rooms and they had access to their team mates only in Second Life via avatars and audio connection. To ensure that each team would be in equal position, the team members did not know one another beforehand and met face-to-face for the first time only after the session. Furthermore, the participants did not receive information about the researchers’ interests at all.
Second Life consists of spaces for social interaction and collaboration built on virtual islands. The space in this study was built on an island that was surrounded by a transparent wall that prevented the participants from leaving the area. The space also included a virtual whiteboard that the teams could jointly use to complete the assigned tasks (see Figure 2). The teams used an audio connection that was continuously open to communicate verbally. Each team used the same three pre-selected avatars for navigating in the space and for using the whiteboard. Although the teams comprised both male and female participants, the avatars had customary male appearances.
In Second Life, the participants can interact through their avatars in two ways: either using a first-person perspective (seeing through the avatar’s eyes) or a third-person perspective, when they can see both themselves and the other avatars from a bird’s eye view. Zooming in and out with a mouse is one way to shift between these perspectives, and it also defines how the interface and the team mates in Second Life appear to the participant. When first-person perspective is used, the participant is unable to see his/her own avatar body, and what they see in the virtual space (objects, other avatars etc.) depends on how close they are (the collaboration space is, however, so small that the participant can always see their team mates’ avatars, if s/he only looks at their direction). For example, if the participant’s avatar stands right next to another avatar, s/he sees only the other avatar’s head; moving further away broadens the view. The third-person perspective allows a broader field of vision: the participant can leave his/her own avatar body and see it, as well as the others, from a distance (as in Figure 2).
In Second Life, walking and running with the avatar are controlled with arrows or the WASD keys on the keyboard. In addition, when the participant clicks on a location with their mouse, the avatar walks there. The whiteboard is activated by clicking on it, and the activation is visible as the avatar raises its arm towards the whiteboard and white dots connect the arm to the whiteboard (as in Figure 2).

Figure 2: Collaboration space from a bird's eye perspective, including avatars and a virtual whiteboard.
Each team participated in an assigned session that started with a brief orientation followed by collaborative and individual assignments. The orientation session aimed to familiarize the participants with the task types as well as Second Life’s basic functionalities and avatar movements, for example how to walk to adjust distance to the whiteboard, how to change the view with the mouse and the ALT-key without moving the avatar, and how to activate the whiteboard. During the actual collaborative work, each team transitioned between two types of activities: collaborative tasks and individual questionnaires (see Figure 3). After each task, each team member was instructed to individually fill in a questionnaire featuring questions about how they perceived themselves, their team mates, and the joint interaction during the preceding task.

Figure 3: Structure of the team sessions.
3.2 Data collection
All teams in the collaboration setting were video-recorded. Each recorded session lasted 2.5 hours, resulting in 30 hours of video data. To capture the team members both in the virtual space as avatars and in their separate physical locations as “real bodies,” video cameras were embedded both in the virtual world (the “VW” videos) and in the physical real-life locations (the “RL” videos). The video data of each team comprises one VW video where the team members interact as avatars, and three separate RL videos that capture each team member in their physical locations (see Figure 4). The first author screen-recorded the VW video from the bird’s eye perspective of her own avatar who was in the virtual space but not visible to the three team members. Cameras in the real-life locations captured the team members’ upper body from the side as well as their computer screens. The cameras were activated from a distance in the beginning of the orientation session. Since the VW video does not capture the team members’ actual views to Second Life, the RL videos were used during the analysis for example to see when the participants shifted between first-person and third-person perspectives.
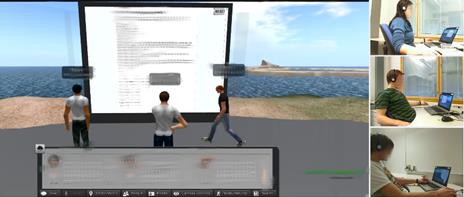
Figure 4: VW and RL videos side by side.
3.3 Data analysis
In our analysis, we applied the principles of multimodal conversation analysis (Goodwin 2000; Mondada 2016). Our analytic steps followed the basic conversation analytic research process (Sidnell 2013). First, we viewed the video recordings multiple times to identify the episodes that grasp our phenomenon of interest: moments of transitions between gatherings and encounters. Gatherings prevailed especially during the questionnaire-filling time; at those moments, the team members focused silently on individual rather than collaborative work. The questionnaire filling moments can be described as “allowable silences” (Hoey 2015), even “planned silences” between the “planned encounters”, i.e., the collaborative tasks.
All participants in the 12 teams filled altogether nine questionnaires, one during the orientation and one after each assigned task (108 questionnaire-filling episodes in total). Most participants were ready sooner than expected, which resulted in unexpected ‘surplus time’ until the next collaborative task began. During this surplus time, the team members either voluntarily initiated an encounter, or waited for the next task in silence. Since there were several possibilities for each team to open an encounter after the silent gatherings, we use the term re-opening to refer to the verbal opening turns in our analysis.
In 40 of these episodes, there was a transition from a gathering to an encounter (i.e., one team member produced a verbal turn, which was always responded to by the others), whereas in 66 of the epi-sodes the surplus time was composed of a gathering only. In these 66 gathering-only episodes, the team members either just waited sitting still and silent (38 episodes), or walked with their avatars in the joint space in silence, not re-opening an encounter verbally (28 episodes). In other words, embodied avatar behavior does not seem to constitute a joint activity for the participants. Furthermore, the VW does not allow for creating a focus of joint attention with embodied means only, as the participants cannot be sure of the others’ attention foci. For these reasons, entirely non-verbal (re‑) openings do not exist in the data. This is a significant and interesting difference compared to face-to-face interaction and furthermore points to a difference in the accountability of different behaviors. In addition, we found two episodes in the data where the team kept up the encounter (i.e., a conversation) during the entire questionnaire-filling episode, even though they were supposed to work individually.
In our detailed analysis, we focused on the 40 gathering−encounter transitions. We transcribed the team members’ verbal communication (using the Jeffersonian conventions; see, e.g., Jefferson 2004) as well as their embodied actions (applying the conventions developed by Mondada 2019), including avatar movements and each team member’s gaze direction, facial expressions, body movements and hand movements on the keyboard (see Appendix for the transcription symbols). Next, we analyzed the sequential and temporal trajectories of the gathering−encounter transitions, described them in detail, and made comparisons across episodes. In what follows, we will present our findings.
It is important to note that in our transcripts, the parts that are based on the RL videos only work as a tool for the analysts and the readers to have additional information about the team members’ actions in their real-life locations. What the participants do in their physical locations “behind” their avatars, such as their gaze direction and hand movements on the keyboard, are never accessible to the other team members. Thus, the participants cannot use these embodied actions as interactional resources but can orient to the others only in the virtual world. In the following data excerpts in Section 4, we have transcribed the activities seen in the RL videos in the beginning of the excerpts to show the exact moments when the participants finish their questionnaires and what they do immediately after finishing. In addition, we have included some RL video transcripts to certain moments of silence where not much happens in the VW.
4 Transitioning from a gathering to an encounter in a virtual world space
In general, the team members were rather cautious about initiating conversation immediately after they had finished their own questionnaires, possibly because there were not always clear signs of whether the others were ready with their questionnaires yet. Rather, the team members stayed silent for several seconds after finishing their own questionnaire. When interacting face-to-face, there are embodied strategies for dealing with “awkward silences” that may occur when continuous conversation lapses. For example, the participants may drink, eat, or engage in self-grooming or yawning (Hoey 2015; Vatanen forthc.). In our data, the team members engaged in similar activities to ‘fill’ the silence or to pass the time when waiting in their separate physical locations. They drank water, yawned, stretched, or changed their body positions in their chairs. By carefully viewing RL videos of each participant, we also observed that some of them explored the virtual space without moving their avatars by using their mouse scroll and the ALT-key to zoom and rotate their view of the virtual space. In addition to these private waiting activities, the team members also started to move their avatars in the virtual space when waiting (cf. Svinhufvud 2018; Ayaß 2020). When a team member finally initiated a conversation after having waited, the re-opening usually related to something other than directly asking whether the others were ready with their questionnaires.
Based on our analysis, the ways in which the participants transition from a gathering to an encounter in the 40 episodes fall into two main types. In Process 1 (12 episodes), the transition is accomplished using verbal means only: in these cases, the encounter simply is verbally re-opened by one of the team members. In Process 2 (28 episodes), the transition involves the use of avatars before the verbal re-opening. All of the verbal turns were responded to, making them sequence-initiating turns; none of them was treated as self-talk (cf. Keevallik 2018). In the following analysis, engaging in avatar movement before the verbal re-opening will be called a virtually embodied pre-beginning. In this VW context, the virtually embodied pre-beginnings have different characteristics compared to the embodied pre-beginnings in face-to-face interaction described by Mondada (2009).
In addition to the two transition processes, there are differences in the verbal re-opening turns. The openings include the social actions of noticing, information-request, account, and proposal; of these actions, noticings and information-requests have been found to be used for (re-)opening encounters also in face-to-face settings where participants alternate between accomplishing individual tasks and talking together (Szymanski 1999).
Topic-wise, the opening actions may be related to the virtual space or to something else such as the other team members, or the tasks and questionnaires in the interaction setting. In Process 2, some of the re-openings are related to the avatar movement which directly precedes the verbal re-opening. The re-opening is also dependent on the type of the preceding avatar movement during the virtually embodied pre-beginning (e.g., walking vs. jumping). Next, we analyze in more detail both transition processes as well as the virtually embodied pre-beginnings and the action types that re-open the encounters.
4.1 Process 1: Transition directly to talk, no virtually embodied pre-beginning
Process 1 includes altogether 12 episodes where the transitioning from a silent gathering to an encounter takes place without any embodied preparation (see Figure 5). In these episodes, someone in the team just starts to talk at some point after finishing his/her own questionnaire.

Figure 5: Process 1 of transitioning from a gathering to an encounter.
The 12 episodes in Process 1 can be divided into two categories according to the social action that is used to re-open the encounter (the first verbal turn): noticing something (4 episodes) and requesting information (8 episodes). The noticings relate to something in the virtual space (cf. Szymanski 1999) whereas the information-requests relate to something else, such as the interaction setting or the other team members.
We illustrate Process 1 by showing an excerpt of noticing something in the virtual space. All our forthcoming data examples comprise both a detailed transcript (e.g., 1a) and a graphic illustration (a comic strip) of the same excerpt (e.g., 1b). The approximate occurrence of each figure in the graphic illustration is marked in the transcript as well. In the following, we call the team members seen in RL videos by pseudonyms, and their avatars in the VW videos by “Name-A” (e.g., Jaakko and Jaakko-A).
Excerpt 1 begins when all team members, Juho, Susanna, and Jaakko, fill their questionnaires in silence (fig. 1 in the comic strip). Juho is the first one to finish (line 2).[1]
Excerpt (1a)[2]: Team 10, questionnaire 1, time 0:32:10.

Excerpt (1b): Team 10, questionnaire 1, time 0:32:10.

After finishing his questionnaire, Juho starts to explore the virtual space by using his mouse scroll and the ALT-key, which does not move his avatar (lines 2–3). 6.7 seconds after Juho finished, Jaakko finishes his questionnaire but does not immediately engage in any detectable waiting activity but rather keeps sitting still, gaze towards his computer screen (line 4). After 6.3 seconds, he clicks his cursor off the whiteboard, which makes his avatar lower its arm from the whiteboard but not move otherwise (line 5). It is noteworthy here that the participants never orient to the team mates lowering their avatars’ arms (they only orient to more visible embodied conduct such as walking away from the whiteboard). Thus the arm movement does not constitute an embodied pre-beginning in the data. Furthermore, in many cases (e.g., Excerpt 6) the avatar does not lower its arm from the whiteboard immediately after the questionnaire is finished but only after a relatively long delay. Thus, it seems that the participants might not even realize their team mates’ arm movements during and after the questionnaire filling.
After clicking his cursor off the whiteboard, Jaakko sits still and gazes towards his screen for 18.6 seconds while Juho keeps scrolling and Susanna still fills her questionnaire (line 5). Then Susanna finishes her questionnaire and detaches her hands from her mouse and keyboard. Simultaneously her avatar lowers its arm from the whiteboard (line 6). Approximately 15 seconds after finishing her questionnaire, Susanna abruptly leans towards her computer screen (line 7). Two seconds later, she produces a verbal turn, informing the others about what she has just seen in the virtual space: a dolphin jumping in the sea on her right, outside the collaboration area (line 8, fig. 2). She thus uses the environment for generating talk (see Bergmann 1990; Hoey 2018; Keevallik 2018). Juho and Jaakko do not provide immediate verbal responses, but they react bodily to Susanna’s opening: Juho starts to rotate his screen view to the right and Jaakko starts to use his keyboard (line 9). After altogether 2.3 seconds, Jaakko responds to Susanna (fig. 3), and only then, with a relatively long delay, Jaakko-A turns its head to his right (line 11, fig. 4). As Jaakko is unable to detect the dolphin (line 11), the encounter continues with Susanna providing a more detailed explanation of the dolphin’s location (line 12).
In other words, here the transition from a gathering to an encounter is accomplished by only talking, without any (virtually) embodied preparations, and the first verbal turn is a noticing of something in the joint visual space. In addition, there were cases in our data where the re-opening turn was a request for information about something that does not relate to the virtual space but something else. Next, we will analyze cases in Process 2 where the transition includes a virtually embodied pre-beginning before the verbal action that re-opens the encounter.
4.2 Process 2: Transition with a virtually embodied pre-beginning
In our data, the participants did not always remain waiting and managing the silence alone in their physical locations but used the waiting time to explore the joint virtual space by moving their avatars. We grouped these cases under transition process 2, which includes altogether 28 episodes where the transitioning from a silent gathering to an encounter takes place with an embodied preparation phase (see Figure 6). This virtually embodied pre-beginning comprises different movements of the avatar.

Figure 6: Process 2 of transitioning from a gathering to an encounter.
The 28 episodes in Process 2 fall into four categories according to the social action that re-opens the encounter. As in Process 1, these actions include noticings (15 episodes) and information-requests (11 episodes), but in addition, also one account and one proposal. Content-wise, the re-openings relate either to the preceding avatar movement, the virtual space, or something else. In these episodes, it was also meaningful to make a difference as to who produces the verbal re-opening: the one who engaged in the avatar movement preceding the verbal turn, or someone else in the team.
The types of virtually embodied pre-beginnings are quite different from the pre-beginnings in face-to-face situations described by Mondada (2009). Instead of subtle body orientations and eye contact with the interlocutor-to-be, the virtually embodied pre-beginnings include walking around in the virtual space, jumping, and bumping into something (another avatar or the virtual whiteboard) with one’s avatar. Let us now examine in more detail the noticings and information requests that re-open the encounters, and the preceding virtually embodied behaviors.
4.2.1 Noticing something after a virtually embodied pre-beginning
In 15 episodes, the re-opening action that followed a virtually embodied pre-beginning was identified as a noticing (on noticings, see Szymanski 1999, Keevallik 2018 and the literature cited therein). These noticings target either the just-preceding avatar movement (8 episodes), something in the virtual space (5 episodes), or something else, in these cases the collaboration session in progress (2 episodes).
The following Excerpt (2) includes a team member’s (Oliver) noticing about his own preceding avatar movement as the re-opening turn. This excerpt begins when all team members, Paula, Selena and Oliver, fill their questionnaires in silence (fig. 1).
Excerpt (2a): Team 1, questionnaire 3, time 1:01:08.

Excerpt (2b): Team 1, questionnaire 3, time 1:01:08.
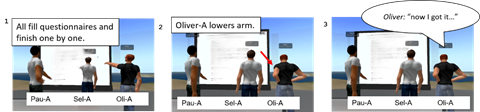
Selena is the first one to finish her questionnaire (line 2). She clicks with her mouse and after a relatively long delay of 2.6 seconds, her avatar lowers its arm from the whiteboard (line 3). Then Selena uses her mouse scroll and the ALT-key to zoom her view to the virtual space for 6.1 seconds, during which her avatar stands still. It is only after she removes her hand from the mouse that her avatar takes a few steps back but does not engage in further movements (line 3). These few steps seem to result from the removal of hand from the mouse and, as such, are unintended or at least not actively produced by Selena. Paula is the next one to finish her questionnaire. Her avatar keeps pointing to the whiteboard even though she detaches her hands from the keyboard (line 4). Oliver finishes last (line 5). After 2 seconds, he clicks with his mouse, which results in his avatar lowering its arm from the whiteboard (line 6, fig. 2). Oliver opens the encounter by sharing his newly-made finding with his team mates (lines 7-8, fig. 3), producing a noticing that begins ‘now I got it’. He does this possibly because Paula had complained earlier during the session that she did not like the dots that appeared between the avatar’s hand and an object, which indicated activation or operation with that object.
This excerpt is the only example in our collection where lowering the avatar’s arm from the whiteboard functions as an embodied pre-beginning to an encounter. Here the lowering movement is something that the team member who did it (Oliver) orients to and uses as a resource for re-opening the encounter; his team mates do not use it as a cue that would indicate his readiness for an encounter.
The following Excerpt (3) includes a noticing about something in the virtual space as the verbal re-opening, and here it is the same team member who first walks with his avatar and then opens the encounter (even though here actually all participants move their avatars prior to the re-opening). This excerpt begins when all team members, Juuso, Filip, and Petra, fill their questionnaires in silence (fig. 1).
Excerpt (3a): Team 3, questionnaire 7, time 2:06:23.

Excerpt (3b): Team 3, questionnaire 7, time 2:06:23.

Here all team members start to move their avatars in the virtual space a few seconds after finishing their questionnaires. Filip finishes first (line 2). After 3.3 seconds of inactivity, he starts to move his avatar for 3.6 seconds (line 3, fig. 2), after which he switches to rotating his screen view with his mouse and the ALT-key, which stops his avatar movement (line 4). Then Juuso finishes his questionnaire and inhales loudly (lines 5-6). He sits still for 2.4 seconds (line 7), then exhales loudly and starts to move his avatar (lines 8–9). For altogether 23.9 seconds, Juuso is the only one to move his avatar, while occasionally also standing still (lines 9–10, fig. 3). Finally, Petra finishes the questionnaire, too, and after 2.5 seconds she starts to move her avatar (lines 11–12, fig. 4). Juuso and Petra move their avatars simultaneously in silence for 9 seconds, after which Petra stops moving (line 12). The pace and direction of their movements seem to be rather random and they do not take any noticeable bodily contact with one another. Juuso continues moving in silence for another 12 seconds (line 12). Then he stops his avatar next to the whiteboard, the avatar facing towards the sea behind the collaboration space (line 13, fig. 5). After 5 seconds, Juuso produces a noticing about a jumping fish he has discovered in the sea (line 14, fig. 6; cf. Bergmann 1990; Hoey 2018; Keevallik 2018). Filip reacts to Juuso’s opening immediately by initiating repair with the question word mitä ‘what’ (line 17). After Juuso partially repeats his preceding turn, Filip responds by pointing out that this discovery is not very novel to him (see line 20).
In summary, in the two excerpts above, the transition to an encounter involved a virtually embodied pre-beginning, and the verbal actions that re-opened the encounter after the preceding avatar movement were noticings about something in relation to the preceding avatar movement and the virtual space. In twelve of the fifteen noticings in our data, the one who moves the avatar also re-opens the conversation (see Excerpts 2 and 3). In three episodes, the one who moves and the one who re-opens the encounter are different people. Next, we analyze a transition again preceded by virtually embodied behavior, with information requests as the opening actions.
4.2.2 Requesting information after a virtually embodied pre-beginning
In eleven episodes, the opening turn was an information request (see also Szymanski 1999 on questions as re-opening actions). To open the encounter, the participants requested information about the preceding avatar movement (2 episodes), about something in the virtual space (3 episodes), or something else, e.g., the collaboration session or the team mates (6 episodes). Similarly to the noticings, the person who engages in moving the avatar and the person who opens the encounter may be the same or a different participant.
In the following Excerpt 4, Juho re-opens the encounter by requesting information about his own avatar’s preceding movement. The excerpt begins when all team members, Juho, Susanna, and Jaakko, fill their questionnaires in silence (fig. 1). Juho is the first to finish the questionnaire (line 2).
Excerpt (4a): Team 10, questionnaire 5, time 1:39:15.

Excerpt (4b): Team 10, questionnaire 5, time 1:39:15.

Juho deactivates his whiteboard 3.8 seconds after finishing the questionnaire, which makes his avatar lower its arm (line 2). Then he starts to explore the virtual space. We see from the RL video that he uses only the ALT-key and mouse that allow him to zoom and rotate the screen view without moving his avatar (line 3). About half a minute after Juho, Jaakko finishes the questionnaire. He deactivates his whiteboard, which makes his avatar take a few steps back; he does not, however, engage in further movements (line 4). After that, he remains sitting still, looking at his computer screen (line 5). Then, Susanna finishes her questionnaire, and one second later, Juho clicks his mouse, which makes his avatar walk across the virtual space, past Jaakko-A and Susanna-A (lines 6–7, fig. 2). Clicking somewhere in the virtual ground with the mouse makes Juho’s avatar walk forward to the clicked location. This movement is apparently unintentional as Juho shares his surprise with others: “I wonder where I started to run all of a sudden” (line 8, fig. 3), and “what’s the matter with this” (line 11). Juho’s questions about his avatar movement re-open the encounter, and Susanna and Jaakko respond with laughter (line 9) and joking (line 12, fig. 4). They also start to use their avatars to turn to look at Juho-A (lines 12–13, fig. 4-5). Juho joins Jaakko’s joking, and the encounter continues (line 14).
In the next Excerpt 5, the encounter is opened by Elisa. She requests information about another team member’s (Jerri) avatar’s preceding movement. Thus, in contrast with the previous excerpt, here the one who engages in the avatar movement and the one who opens the encounter are different team members. The excerpt begins when all team members, Tanja, Elisa, and Jerri, fill their questionnaires in silence (fig. 1). Tanja is the first one to finish the questionnaire (line 2).
Excerpt (5a): Team 9, questionnaire 1, time 00:34:34.

Excerpt (5b): Team 9, questionnaire 1, time 00:34:34.

For 5.5 seconds after finishing the questionnaire, Tanja sits still (line 2) but then inhales audibly (line 3) and starts to use her keyboard and walk in the virtual space with her avatar (line 4, fig. 2). Elisa finishes next and remains sitting still, looking at her screen (line 8). After she has been silent for 6 seconds, Tanja-A appears in front of the whiteboard and walks near the other avatars (line 8). Although it is not certain whether Elisa notices Tanja’s avatar, she starts to move her avatar right after Tanja-A appeared near her avatar (line 9, fig. 2). Jerri finishes his questionnaire as well and immediately starts to move his avatar (lines 10–12, fig. 3). All team members move together in silence for 6 seconds (line 12). Then Jerri suddenly jumps high up with his avatar (line 12, fig. 4). Elisa reacts to this by laughing and asking how Jerri managed to jump (line 13, fig. 5). Once Jerri has responded that the E button in the keyboard makes the avatar jump (line 14, fig. 5), Elisa tries out jumping as well (line 15), and the encounter continues.
In six episodes, we witnessed some preceding avatar movement but the opening turn did not concern it or anything in the virtual space, but something else. Excerpt 6 is an example of such a transition. The person who moves and the person who opens the encounter are different. In addition, Excerpt 6 is a rare case where the opening relates to a prior discussion topic (the team members’ free time). The excerpt begins when all team members, Paula, Selena, and Oliver, fill their questionnaires in silence (fig. 1).
Excerpt (6a): Team 1, questionnaire 6, time 1:58:28.

Excerpt (6b): Team 1, questionnaire 6, time 1:58:28.

Oliver is the first one to finish his questionnaire. He does not immediately engage in moving his avatar other than lowering its arm from the whiteboard (line 2). Selena finishes next (line 4). Then she exhales audibly and withdraws from her computer (line 5). Paula is the last one to finish (line 6), and 1.3 seconds later Oliver starts to use his keyboard to walk around with his avatar (line 7, fig. 2). Now Selena returns to gaze towards her computer screen, and 1.6 seconds later, Oliver stops his avatar movement behind Paula-A and Selena-A (line 8, fig. 2). After 1.3 seconds Selena inhales and exhales noticeably (line 9, fig. 3). Thus, the opening of the ensuing encounter, Paula’s long question (lines 10-11, fig. 3), is preceded by an audible in- and outbreath by a co-participant. The opening itself relates to something else than the avatar movement or the virtual space: the team members’ free time. This case is one of the episodes where the opening turn does not initiate a completely new topic but relates to a previous one: Selena has relayed that she has used the dating application Paula talks about during one of their previous task assignments. Paula’s opening is thus understood as addressed to Selena, even though it is not certain if she could identify the preceding outbreath to be produced by Selena.
In this excerpt, Oliver’s prior avatar movement does not seem to relate to Paula’s opening turn, which was, after all, addressed to Selena. It is, however, possible that witnessing someone moving with an avatar can be used as a cue for detecting that at least one team mate is ready with her/his questionnaire and thus available for an encounter (the same occurred in Excerpt 3). In addition, the audible breathing may have affected the timing of the verbal opening turn.
In summary, in the three excerpts above, the transition to an encounter involved a virtually embodied pre-beginning, and the actions that re-opened the encounter were information requests about the avatar movement or something else. In six of these eleven information request episodes, the same person who moves the avatar also opens the encounter (see Excerpt 4). In five episodes, the team member who moves and the team member who opens the encounter are different (see Excerpts 5 and 6). Next, we present the implications of the virtually embodied behavior in VWs as indicating what we call encounter-readiness, after which we provide a summary and discussion of our findings.
5 Virtually embodied behavior indicates encounter-readiness
Previous studies on interaction in VWs have not been unanimous in how and to what extent virtually embodied behavior is actually used alongside verbal communication. Researchers have claimed that although people interact in a VW as avatars surrounded by virtual objects, they still mainly use talk in their communication (Sivunen/Nordbäck 2015). On the other hand, some studies also suggest that the possibility to use simultaneously text, audio, objects, and the avatar body is the key to enriching discussions and structuring interaction (Antonijevic 2008), and to increasing the awareness of others (Allmendinger 2010). Some studies suggest that avatar stillness may signal even the lack of presence of the user behind the avatar (Bennerstedt/Ivarsson 2010) or false availability of the user (Moore et al. 2006). The findings of the current study shed more light on the role of virtually embodied behavior in moments when people in the VW have been silent, i.e., in a ‘gathering’, and are about to (re-)start talking.
Our findings suggest that the role of virtually embodied behavior is to function as a possible pre-beginning of an encounter: it signals one’s readiness with the preceding individual task and the availability to move to an encounter, i.e., to interact with others. We call the engagement in the virtually embodied behavior encounter-readiness. Displaying and witnessing encounter-readiness seems to be an important cue for co-participants in considering opening an encounter. There are certain reasons for this, and some of them seem to do with certain functionalities of the present VW, Second Life. When the team members operate with the whiteboard, their avatar’s arm points towards the whiteboard, and dots appear from the avatar’s hand to indicate the activation of the whiteboard. When a team member stops activating the whiteboard, the avatar’s arm should be lowered. An avatar automatically lowers its arm and just stands still after certain, sometimes a relatively long amount of time not being operated by the user. However, as we saw in some excerpts above, it was rather common that although a team member had completed the questionnaire, the avatar kept touching the whiteboard (e.g., Excerpt 6). Thus, it seems that if avatars were not moved elsewhere after completing the questionnaire, the team members had very few cues about whether the others were ready or not (in case they did not directly ask about it, which occurred only once in our data).
Our findings on virtually embodied behavior are consistent with Bennerstedt and Ivarsson’s (2010) observation about the use of avatar jumping between phases in games. According to them, during waiting periods in games, the players used avatar jumping to signal to the others that they were still in the game and had not left their avatar hanging behind. Our data, too, involve cases of jumping as a waiting activity (see Excerpt 5).
In addition, presence in a joint space seems to be essential for embodied pre-beginnings to function. In their study of interaction in a media space where remote participants were continuously co-present over video connection but not situated in a joint space, Heath and Luff (1992) found that embodied pre-beginnings of encounters, such as glances, or solely embodied openings, such as waves, were rarely successful. In the continuously open media space, monitoring others’ availability for an encounter seems effortless over video, whereas embodied attempts to actively move to an encounter often passed unnoticed by the intended recipients. The apparent reason for the diminished impact of embodied cues can be best explained with the “fractured ecology” of the situation: the physical environment where the action is produced is not the same where it is received – a flat screen (Luff et al., 2003). In virtual worlds where the participants share the same space, embodied actions and movements might be easier to detect than in the above described media space, although in virtual worlds the exact focus of others’ attention might be more difficult to determine.
Altogether, our findings suggest that (re-)opening an encounter is more often preceded by virtually embodied behavior (28 episodes in Process 2) than by the participants’ avatars just remaining still (12 episodes in Process 1). However, as mentioned in Section 3.3 above, our data also included 66 episodes where the ‘surplus time’ consisted of a gathering only, and no transition to an encounter occurred. These gatherings were of two types: waiting privately in silence for the next task (38 episodes), or walking with the avatar in the joint space but not opening an encounter (28 episodes). Some of these “gatherings” resemble certain moments in face-to-face interaction where the participants do not talk or do anything bodily but are nonetheless committed to being together at that moment, i.e., to the co-presence (see Vatanen, forthc.).
These types of moments actually challenge the idea of dividing social situations strictly into the two categories of gathering and encounter. Rather, participant behavior in social situations seems to be better described as a continuum of orientations (see Vatanen, forthc.). Somewhere in between focused encounters and unfocused gatherings are situations where the participants do not sustain a joint focus of attention, such as a conversation or another mutually coordinated activity, but nevertheless are committed to being co-present and together in the shared space − such as here the participants’ commitment to accomplishing the whole collaboration session as a team. At these moments, the participants are physically − or, virtually − in the same space where they have just previously had a focused encounter, when the nature of the situation transforms into one where the togetherness and joint focus are more fragile than they are in an encounter but stronger than in a gathering. (For more discussion and an example of such a situation in face-to-face interaction, see Vatanen, forthc.) In face-to-face interaction, the participants’ orientations to one another and the co-presence can be traced observing their bodily behaviors, whereas in mediated co-presence such as a VW, the orientations are more difficult to prove, both for the analyst and especially for the participants who only have access to the co-participants’ avatars. This seems to be related to the significance that avatar behavior has for opening an encounter, which was discussed in the current study.
Comparing the 28 episodes where virtually embodied behavior was followed by an opening of an encounter (in Process 2), and the 28 episodes of avatar(s) walking but remaining in a gathering-like situation (or in a situation that seems to be in between the two situation types), it seems that moving with the avatar indeed signals only availability or possibility for an encounter but does not automatically lead to it. For this reason, we conclude that virtually embodied behavior works only as a signal about readiness to move to an encounter, and it is up to the participants whether then to open an encounter or not. Consequently, not all virtually embodied behaviors can be called encounter pre-beginnings either; rather, that particular characterization can be done in retrospect only.
6 Summary and discussion
This study focused on the details of how gatherings turn into encounters in a VW. We aimed to further the empirical investigations of social interactions in VWs, especially by treating what in the field of computer-mediated communication has been called social presence (i.e., an encounter) as a behaviorally displayed entity. We applied multimodal conversation analysis to examine the interactional practices that participants use in the gathering−encounter transitions. In our data, two main types of transition processes occur. First, there are episodes where the transition happens by one participant directly starting to talk, without any preceding virtually embodied behavior (Process 1). However, it is more common that the transition includes a virtually embodied pre-beginning phase that is then followed by verbal interaction (Process 2).
Compared with Mondada’s (2009) and Mondada and De Stefani’s (2018), our findings suggests that there are certain differences in how gatherings turn into encounters in a VW compared to face-to-face situations. Unlike in face-to-face situations (ibid.), in our data the interactional space was not stabilized at the end of the embodied pre-beginning, before the verbal (re-)opening turn. In our setting, the physical participants are rather stable behind their screens, but their avatars may keep moving when transitioning from a gathering into an encounter (and even during an encounter). The situation and the use of embodied resources are very different in a VW, and consequently, stabilizing the setting does not play a similar role. Furthermore, space and the avatar body seem to have different roles for establishing interactional space in a VW: movement in space helps to signal availability, whereas standing still signals a potential lack of (psychological) presence of the participant behind the avatar.
The interaction setting we studied is different from Mondada’s (2009) also in other respects. Unlike Mondada, we did not study the very first encounters between strangers, or even unplanned encounters between acquainted persons (De Stefani/Mondada 2018). Rather, even though the participants in our setting were strangers to one another at first, they little by little became more acquainted with one another. They were also present with one another as avatars in a joint location the whole time, not briefly passing one another on a street. De Stefani and Mondada (2018) showed that people engage in interaction in a different manner depending on whether they interact with acquainted or unacquainted persons, which also has organizational consequences for the openings. In our setting, it was intriguing that the incremental familiarization of members within the teams did not seem to affect the ways in which encounters were re-opened time after time. Even though each team had the possibility to transition from a gathering to an encounter nine times during the whole collaboration session, the team members remained careful not to open the encounter immediately after finishing their own questionnaires, but usually only after several seconds and only after exploring the virtual space privately or by moving their avatars. In addition, such openings that would reveal any emerging acquaintanceship between the participants were rare (e.g., asking about the study fields of others). Thus, the incremental familiarization of the team members during the sessions did not seem to have consequences for how the encounters were re-opened; probably they could not achieve a sufficient level of familiarization after only 2.5 hours of interacting in comparison with the persons in De Stefani and Mondada’s study.
Our study also contributes to the prior literature on how interaction is resumed after it has been ceased for a moment. Previous research has detected three ways to resume interaction after a lapse in talk: participants may move to end the interaction, continue with prior talk, or start something new (Hoey 2018). In our data, it was interesting that the re-opening turn usually did not continue any prior topic (this happened in only six of the 40 episodes). Most often the participants opened the encounter by starting something new, often using the virtual environment as a resource for generating talk - as has been found to happen after silences in face-to-face situations (Bergmann 1990; Keevallik 2018). The environment-based openings concerned the joint virtual space and objects to which all team members had access, and in Process 2, the preceding avatar movement as well. The rest of the openings related usually to the interaction setting or other team members. Furthermore, the social actions of the re-opening turns in our data were mostly noticings and information-requests (also one account and one proposal) – in other words, a wider variety of actions compared to those observed in Mondada (2009) and De Stefani and Mondada (2018), but similar to those found by Szymanski (1999).
In the studied VW setting, a verbal turn by a participant was always responded to. Thus, contrary to the face-to-face setting investigated by Keevallik (2018), the participants never treated their team mates’ turns as self-talk in the VW (with the exception of a single jes ‘yes’ particle turn that received no response). The reason for this might be that in a face-to-face situation, the participants orient to subtle differences in one another’s embodied behavior as accountable and meaningful, whereas the avatars’ virtual embodiment is much less sophisticated and, perhaps for that reason, not oriented to as similarly accountable behavior. Relatedly, verbal communication may then gain more importance in the interaction.
Our study illustrates how different kinds of avatar movements, such as walking and jumping, have different consequences for the following interaction. Walking with the avatar seemed to help a team member to notice things in the virtual space and then to use this information to re-open an encounter. In addition, witnessing walking seemed to work as a hint for the co-participants that the walker is ready with their questionnaire and thus available for an encounter. However, witnessing walking did not lead into initiating conversation, whereas witnessing playful avatar behaviors such as jumping was reacted to by other team members and thus invited others to open an encounter. A reason for this may be that unlike jumping, walking was familiar for all participants as they were instructed on that during the orientation session. Thus, co-present team members treated walking with “civil inattention” (Goffman 1963: 84), as would be done in gatherings on the street, for example. Furthermore, both walking and jumping functioned as “waiting behaviors” in our data (cf. Svinhufvud 2018; Ayaß 2020).
Our findings also elaborate Mennecke et al.’s (2011) theory on embodied social presence which implies that VW affordances such as avatar body, virtual space, and virtual objects as well as verbal and nonverbal communication need to be used to transition from ‘co-presence’ to ‘social presence,’ i.e., from a gathering to an encounter. However, this theory does not explicitly focus on the ways in which the VW affordances are used to achieve this transition. Our study thus offers a major new insight into this topic.
Future research could explore how familiarity with one’s avatar and the space might influence the ways in which encounters are (re‑) opened in VWs as well as in constant virtual teams where the members know one another well. Familiarity might also increase the intentionality of one’s avatar movements. In our study, we observed avatar behaviors that seemed intentional and those that did not, while both seemed to function as embodied pre-beginnings in the data (see unintentional movement e.g. in Excerpt 4). Especially newbie users might find it difficult to assess the connections between their mouse and keyboard actions and the avatar movements, and their consequences. Thus, it would be worth investigating in more detail how the participants produce, and orient to, different types of avatar movements and treat them as public and socially meaningful. In addition, the transition from a gathering to an encounter in “public” VW spaces where the participants resemble more the passers-by in Mondada’s (2009) article should be studied.
Appendix: Transcription conventions
Verbal communication (based on Jefferson 2004):

Embodied behavior (adapted from Mondada 2019):

References
Allmendinger, Katrin (2010): Social Presence in Synchronous Virtual Learning Situations: The Role of Nonverbal Signals Displayed by Avatars. In: Educational Psychology Review 22, 41–56.
https://doi.org/10.1007/s10648-010-9117-8
Antonijevic, Smiljana (2008): From Text to Gesture Online: A micro-ethnographic analysis of nonverbal communication in the Second Life virtual environment. In: Information, Communication & Society 11 (2), 221–238.
https://doi.org/10.1080/13691180801937290
Ayaß, Ruth (2020): Doing Waiting: An Ethnomethodological Analysis. In: Journal of Contemporary Ethnography 49 (4), 419–455. https://doi.org/10.1177/0891241619897413
Benford, Steve/Fahlén, Lennart (1993): A Spatial Model of Interaction in Large Virtual Environments. In: Proceedings of the Third European Conference on Computer-Supported Cooperative Work, 109–124. https://doi.org/10.1007/978-94-011-2094-4_8
Bennerstedt, Ulrika/Ivarsson, Jonas (2010): Knowing the Way. Managing Epistemic Topologies in Virtual Game Worlds. In: Computer Supported Cooperative Work (CSCW) 19 (2), 201–230.
https://doi.org/10.1007/s10606-010-9109-8
Berger, Israel/Viney, Rowena/Rae, John P. (2016): Do continuing states of incipient talk exist? In: Journal of Pragmatics 91, 29–44.
https://doi.org/10.1016/j.pragma.2015.10.009
Bergmann, Jörg R. (1990): On the local sensitivity of conversation. In: Markovà, I./Foppa, K. (eds.): The Dynamics of Dialogue. Hemel Hempstead: Harvester Wheatsheaf, 201–226.
Biocca, Frank/Harms, Chad/Burgoon, Judee (2003): Toward a more robust theory and measure of social presence: Review and suggested criteria. Presence: Teleoperators and Virtual Environments 12 (5), 456–480.
https://doi.org/10.1162/105474603322761270
Broth, Mathias/Keevallik, Leelo (2014): Getting ready to move as a couple: Accomplishing mobile formations in a dance class. In: Space and Culture 17 (2), 107–121.
https://doi.org/10.1177/1206331213508483.
De Stefani, Elwys/Mondada, Lorenza (2018): Encounters in Public Space: How Acquainted Versus Unacquainted Persons Establish Social and Spatial Arrangements. In: Research on Language and Social Interaction 51 (3), 248–270.
https://doi.org/10.1080/08351813.2018.1485230
Goffman, Erving (1959): The presentation of self in everyday life. New York: Anchor Books.
Goffman, Erving (1963): Behavior in public places. New York: The Free Press.
Goodwin, Charles (1984): Notes on story structure and the organization of participation. In: Atkinson, J. M./Heritage, J. (eds.): Structures of social action. Cambridge: Cambridge University Press, 225–246.
Goodwin, Charles (2000): Action and embodiment within situated human interaction. In: Journal of Pragmatics 32 (10), 1489–1522.
https://doi.org/10.1016/S0378-2166(99)00096-X
Heath, Christian (1984): Talk and recipiency: sequential organization in speech and body movement. In: Atkinson, J. M./Heritage, J. (eds.): Structures of Social Action. Cambridge: Cambridge University Press, 247–265.
Heath, Christian/Luff, Paul (1992): Media space and communicative asymmetries: Preliminary observations of video-mediated interaction. In: Human–Computer Interaction 7 (3), 315–346.
https://doi.org/10.1207/s15327051hci0703_3
Hoey, Elliot (2015): Lapses: How People Arrive at, and Deal With, Discontinuities in Talk. In: Research on Language and Social Interaction 48 (4), 430–453.
https://doi.org/10.1080/08351813.2015.1090116
Hoey, Elliot (2018): How Speakers Continue with Talk After a Lapse in Conversation. In: Research on Language and Social Interaction 51 (3), 329–346.
https://doi.org/10.1080/08351813.2018.1485234
Jefferson, Gail (2004): Glossary of transcript symbols with an introduction. In: Lerner, G. (ed.): Conversation analysis: Studies from the first generation. Amsterdam: John Benjamins, 13–31.
Kamunen, Antti (2019): How to Disengage: Suspension, Body Torque, and Repair. In: Research on Language and Social Interaction 52 (4), 406-426.
https://doi.org/10.1080/08351813.2019.1657287
Keevallik, Leelo (2018): Sequence Initiation or Self-Talk? Commenting on the Surroundings While Mucking out a Sheep Stable. In: Research on Language and Social Interaction 51 (3), 313–328. https://doi.org/10.1080/08351813.2018.1485233
Keisanen, Tiina/Rauniomaa, Mirka/Siitonen, Pauliina (2017): Transitions as sites of socialization in family interaction outdoors. In: Learning, Culture and Social Interaction 14, 24–37.
https://doi.org/10.1016/j.lcsi.2017.05.001
Kohonen-Aho, Laura/Alin, Pauli (2015): Introducing a video-based strategy for theorizing social presence emergence in 3D virtual environments. In: Presence: Teleoperators and Virtual Environments 24 (2), 113–131.
https://doi.org/10.1162/PRES_a_00222
Lombard, Matthew/Ditton, Theresa (1997): At the Heart of It All: The Concept of Presence. Journal of Computer-Mediated Communication 3 (2).
https://doi.org/10.1111/j.1083-6101.1997.tb00072.x
Luff, Paul/Heath, Christian/Kuzuoka, Hideaki/Hindmarsh, Jon/ Yamazaki, Keiichi/Oyama, Shinya (2003): Fractured Ecologies: Creating Environments for Collaboration. In: Human-Computer Interaction 18 (1), 51–84.
https://doi.org/10.1207/S15327051HCI1812_3
Mennecke, Brian/Triplett, Janea/Hassall, Lesya/Conde, Zayira/ Heer, Rex (2011): An examination of a theory of embodied social presence in virtual worlds. In: Decision Sciences, 42 (2), 413–450.
https://doi.org/10.1111/j.1540-5915.2011.00317.x
Mondada, Lorenza (2009): Emergent focused interactions in public places: A systematic analysis of the multimodal achievement of a common interactional space. In: Journal of Pragmatics 41 (10), 1977–1997. https://doi.org/10.1016/j.pragma.2008.09.019
Mondada, Lorenza (2012): Coordinating action and talk-in-interaction in and out of video games. In Ayaß, R./Gerhardt, C. (eds.): The Appropriation of Media in Everyday Life. Amsterdam: John Benjamins, 231–270.
Mondada, Lorenza (2013): Interactional space and the study of embodied talk-in-interaction. In: Auer, P./Hilpert, M./Stukenbrock, A./Szmrecsanyi, B. (eds.): Space in language and linguistics. Berlin: de Gruyter, 247–275.
Mondada, Lorenza (2016): Challenges of multimodality: Language and the body in social interaction. In: Journal of Sociolinguistics 20 (3), 336–366. https://doi.org/10.1111/josl.1_12177
Mondada, Lorenza (2019): Conventions for multimodal transcription. Retrieved from:
Moore, Robert/Ducheneaut, Nicolas/Nickell, Eric (2006): Doing Virtually Nothing: Awareness and Accountability in Massively Multiplayer Online Worlds. In: Computer Supported Cooperative Work (CSCW) 16 (3), 265–305.
https://doi.org/10.1007/s10606-006-9021-4
Mortensen, Kristian/Hazel, Spencer (2014): Moving into interaction – Social practices for initiating encounters at a help desk. In: Journal of Pragmatics 62, 46–67.
https://doi.org/10.1016/j.pragma.2013.11.009
Råman, Joonas (2018): The Organization of Transitions between Observing and Teaching in the Budo Class. In: Forum: Qualitative Social Research 19 (1).
https://doi.org/10.17169/fqs-19.1.2657
Sacks, Harvey/Schegloff, Emanuel/Jefferson, Gail (1974): A simplest systematics for the organization of turn-taking for conversation. In: Language 50 (4), 696–735. https://doi.org/10.2307/412243
Schegloff, Emanuel (1979): Identification and Recognition in Telephone Conversation Openings. In Psathas, George (ed.): Everyday Language: Studies in Ethnomethodology. New York: Irvington Publishers, 23-78.
Schegloff, Emanuel (1998): Body torque. In: Social Research 65, 535–596.
Schegloff, Emanuel/Sacks, Harvey (1973): Opening up closings. In: Semiotica 4, 289-327.
Schroeder, Ralph (2008): Defining Virtual Worlds and Virtual Environments. In: Journal of Virtual Worlds Research 1 (1), 1–3.
http://dx.doi.org/10.4101/jvwr.v1i1.294
Schultze, Ulrike (2010): Embodiment and presence in virtual worlds: A review. In: Journal of Information Technology 25 (4), 434–449.
https://doi.org/10.1057/jit.2010.25
Schultze, Ulrike/Brooks, Jo Ann (2019). An interactional view of social presence: Making the virtual other “real.” In: Information Systems Journal 29 (3), 707–737. https://doi.org/10.1111/isj.12230
Sidnell, Jack (2013): Basic Conversation Analytic Methods. In: Sidnell, Jack/Stivers, Tanya (eds.): The Handbook of Conversation Analysis. Chichester: Blackwell Publishing, 77–99.
Sivunen, Anu/Nordbäck, Emma (2015): Social Presence as a Multi-Dimensional Group Construct in 3D Virtual Environments. In: Journal of Computer-Mediated Communication 20 (1), 19–36.
https://doi.org/10.1111/jcc4.12090
Svinhufvud, Kimmo (2018): Waiting for the customer: Multimodal analysis of waiting in service encounters. In: Journal of Pragmatics 129, 48–75.
https://doi.org/10.1016/j.pragma.2018.03.002
Szymanski, Margaret H. (1999); Re-engaging and Dis-engaging Talk in Activity. In: Language in Society 28 (1), 1–23.
https://doi.org/10.1017/S0047404599001013
Szymanski, Margaret H./Vinkhuyzen, Erik/Aoki, Paul M./Woodruff, Allison (2006). Organizing a remote state of incipient talk: Push-to-talk mobile radio interaction. In: Language in Society 35, 393-418.
Vatanen, Anna (2018): Trajectories of embodied activities and the management of lapses. Paper presented at the 5th International Conference on Conversation Analysis (ICCA2018), Loughborough, UK. 11–15 July.
Vatanen, Anna (2020): The interaction order of silent moments in everyday life: Lapses as joint embodied achievements. In Buchholz, Michael/Dimitrijevic, Aleksandar (eds.): Silence and silencing in psychoanalysis: Cultural, clinical, and research perspectives. Relational Perspectives Book Series. Routledge, 307-332.
Vatanen, Anna (Forthcoming, 2021): Co-presence during Lapses: On “Comfortable Silences” in Finnish Everyday Interaction. In: Lindström, Jan/Laury, Ritva/Peräkylä, Anssi/Sorjonen, Marja-Leena (eds.): Intersubjectivity in action. Amsterdam: John Benjamins.