
Vol 8 (2026), No 2: 36–72
DOI: 10.21248/jfml.2026.73
Discussion paper available at:
https://dp.jfml.org/2025/opr-kutzner-schindler-
writing-a-fairy-tale-with-a-little-help-of-chatgpt/
Writing a Fairy Tale with a Little Help of ChatGPT – Prompting Experiences of Fourth-Graders
Abstract
In our article, we analyse prompt protocols that were collected in a study at a local primary school. 24 fourth-graders wrote a fairy tale in pairs of two and used GPT-4o for their text production. The prompt protocols (n=11) offer an insight into the writing process and show that prompting is not only an important writing skill in the age of AI but is also quite complex. To describe its complexity, we use a linguistic methodology analysing each prompt (n=92) produced by the writers. The analysis identifies three primary prompt procedures – imperative requests, polar (yes-no) questions, and wh-questions – which account for over 80 % of all utterances. A formalism is introduced to encode the structure and function of these prompts systematically, revealing patterns such as quantification, specification, and content targeting. Prompt use is further examined in relation to the resulting pupils’ texts, with a typology distinguishing between complete and partial adoptions of AI output.
Keywords: prompt protocols, prompt procedures, prompting strategies, writing strategies, creative writing
1 Introduction0F[1]
Should children in primary school use generative AI technology such as GPT-4o in school for writing texts or should they rather write (and learn) without digital help? To address this question, it is necessary to understand what exactly pupils do when they use generative AI for writing: How do they incorporate the tool into their writing process? Is their use meaningful with regard to the writing process and/or the text product? And do they develop new or different writing competencies in this context; and if so, what do these competencies look like?
With the announcement of ChatGPT by CEO Sam Altman in November 2022, not only the business, medical, and private sectors were rapidly transformed – it rather quickly became clear that education was also affected, and in multiple ways (cf. Buck/Limburg 2023; de Witt/Gloerfeld/Wrede 2023): Pupils use generative text production tools for supporting (or doing) their homework, teachers use it to generate material, give feedback or plan lessons, parents want their children to deal with future technology and be prepared for new work requirements (cf. Vodafone Stiftung 2023). Since the release of ChatGPT, multiple tools with new technologies have been published continuously and users are astonished when it comes to their broad functionalities, although they are not without flaws (e.g. they hallucinate facts or provide bad examples).
Beyond questions of immediate individual benefit, however, researchers and educators must address more fundamental issues: Which competencies remain essential in the era of AI? Are there new or altered competencies that student writers need to develop? Conversely, which competencies might be at risk of being reduced or lost when AI tools are used in specific ways (cf. Niloy et al. 2025)? Finally, how should future teachers be prepared to foster AI literacy in writing education – especially given that the concept itself is still being defined and modelled (see, for example, Alles et al. 2025; Knoth et al. 2024)?
Against this background, the present article provides insights into pupils’ AI-supported writing processes and practices in a classroom setting in which primary school pupils (aged nine to ten) used GPT-4o to collaboratively write their own fairy tales. Their writing process was documented through chat logs, and the resulting written texts were collected for analysis. By analysing these interactions, we aim to contribute to a more fine-grained understanding of how pupils use generative AI while writing and to offer an empirical point of departure for approaching the questions outlined above.
Despite the fact that the setting is unique, we think it is particularly interesting as it can provide a reference point for some important questions: The discussion about enabling younger children to use AI is rather intense: In January 2024, in the expert report of the scientific board of the German Educational Conference (cf. SWK 2024), the highest ranked decision committee concerning the Education Sector in Germany, recommended to use AI only from 7th or 8th grade on (13 to 14 year old pupils) – not earlier.
In the first part of our article (Chapter 2) we will sketch the general framework with a focus on the German school system. In the second part (Chapter 3) we will present our research, which took place in a primary school in North Rhine-Westphalia with 24 pupils. In the third part (Chapter 4) we will analyse the data and by that offer an approach that will take into consideration the specific type of writing interaction in this scenario. In the conclusion (Chapter 5) we will answer the question whether children in primary school should use AI technology and what competencies they need to use it effectively.
Preliminary remark: This article has to deal with at least three challenges that also affect a lot of publications in this field nowadays. First, the technical development concerning AI writing tools is very dynamic. The findings could quickly be overturned by a newer writing tool that works differently. For example: At the beginning, ChatGPT 3.5 was not very accurate and hallucinated sources that did not exist (even though the term hallucination doesn’t seem absolutely accurate see Emsley 2023), a major problem for writing scientific papers with the aid of ChatGPT. With later versions this problem seemed to be less crucial. Additionally, the reasoning models give an insight into the research process and work with sources that can be easily verified. However, new research shows that famous Chatbots like ChatGPT or Bing are tempered with propaganda and fake news articles.1F[2] The need for writers to check the output is still necessary and will become even more important. Second, as AI is a global phenomenon and is widely discussed, new research is emerging quickly (see e.g. Leiter et al. 2024). It is rather hard to keep up with the new findings, and although education also has a national or regional focus, it is important to receive international studies and learn from them (cf. Memarian/Dolech 2023). At this point, it is important to acknowledge that global disparities are also reflected in the language. AI tools tend to perform significantly better in languages that are spoken more widely, such as English or German. This has implications: children whose first language is less commonly spoken may face greater challenges in developing AI literacy.2F[3] Thirdly, the users change as well. In the beginning of the worldwide known phenomenon (years 2022 to 2023) a lot of users tested and explored generative AI. Now pupils use it in school contexts more systematically and start using it earlier and in a broader sense. That means that our findings might be very specific for the concrete situation the pupils are in, and they might be outdated quickly as the technology advances and the competencies of users do as well.
2 Framework: Writing with AI in Primary School
2.1 General Framework
Very shortly after the public announcement that a free version of ChatGPT would be made available for use in November 2022, the first German Federal States published guidelines for teachers and schools, e.g. North-Rhine Westphalia accompanied its guidelines3F[4] with a Moodle (a teaching and learning platform) course. In all of these documents (see also Schindler 2024) teachers are supported in using AI and being open for different applications inside and outside the classroom.
Although a guideline has no legal obligation (for teachers or schools), it is seen as a framework that ought to be implemented and might be followed by a more regulated approach later. In spite of this rather positive attitude towards the use of AI in the classroom, there are some (legal and technical) challenges. Schools as public institutions do have to take into account regulations by general data protection (in German: DSGVO), a European law that specifies which personal data can be collected and further processed.4F[5] Most of the commercial and popular AI tools such as ChatGPT do not fulfil these requirements. This creates a complex situation for dedicated teachers to navigate between the use of and discussion about AI in the classroom and the consideration of sensitive data of pupils (see also Gredel/Pospiech/Schindler 2024; Helm/Hesse 2025). Additionally, the EU AI Act is also obligatory for schools5F[6], although it is still unclear how schools will be affected by that. Besides these European, national and regional guidelines and the mandatory laws, the federal government gave some sort of guidance that is already more concrete: the above-mentioned expert report in January 2024 and the guideline in October 2024. These documents confirm an orientation towards an open-minded approach to AI inside and outside the classroom. It is assumed that teaching, learning and testing will be deeply influenced by AI, while at the same time calling for schools to develop new and different types of examinations. Even though this sounds rather innovation-friendly, the paper is not that specific about the implementation of AI in the classroom or the consequences this might have.
In 2025, these regulations are extended by a new instrument of implementing AI in school and researching its impact on learning and understanding school content: In different federal states of Germany the government funds schools that try out different AI tools. This try out is accompanied by a research study – in North-Rhine Westphalia 25 secondary schools were selected and are now (the programme started February 2025) taking part in this research project that is designed for a duration of two years6F[7] but restricted to High Schools (from grade 5 to 10), in the Federal State of Schleswig-Holstein ten schools participate.7F[8] Besides these examples that are funded by the public sector, there are also networks organised by private foundations, like the Bosch Stiftung8F[9] or self-organised networks like the think tank “Schule” within the VK:KIWA.9F[10] Primary schools, however, are still rather underrepresented. Although there are some very committed teachers who interact and share ideas mainly via social media, the focus on younger learners remains limited. These teachers (like Kristin van der Meer) have a broad audience and discuss AI in primary schools (under @vandermeer_sisters, they have more than 6,000 Follower on Instagram).
2.2 AI and Writing in the Classroom – New Findings and Open Questions
Since 2022, the number of pupils using AI tools has increased drastically. Despite a near infinite choice of AI tools, a large majority of pupils only uses some tools, mostly rather generic chat tools like ChatGPT or Bing or tools that are specifically engineered for translations like DeepL. The findings are more or less universal: The results from a large Swedish study, Malmström et al. (cf. 2023), with 5984 participants, are confirmed in the German studies by Hackl (2025) with 250 students and Helm/Hesse (cf. 2024) with 505 students. Even undergraduates do not necessarily use the tools systematically for their writing process (cf. Helm/Hesse 2025), possibly due to the fear of ban on these tools in examination contexts or because of a lack of knowledge. Despite the regulations, students see quite a lot of advantages, mostly the accessibility, adaptability and simplicity of these writing tools (cf. Phan 2023); in a study with ninth-graders, pupils rate GPT-4o as “easy” and “helpful” (cf. Kutzner 2026). Whether they really use these tools outside of an experimental context depends on their expectations towards performance and effort, but also on social influence and facilitating conditions (cf. Tian et al. 2024). The conditions at school and university vary, there is still – at least for Germany – no real overview about the specific requirements at every higher education institution (cf. Weßels 2025) or schools in general: AI tools might be allowed or forbidden for certain writing assignments, they might generally be available or pupils have to create their own accounts or pay for them, and finally, teachers and professors might encourage their use and develop use cases or ignore AI completely.
Concerning the effect of learning and writing: It seems that the use of generative tools has some positive effects on learning and performance, it can increase the creativity of individuals but seems to decrease the collective diversity (cf. Doshi/Hauser 2024; Niloy et al. 2023).
In the last months several publications have been released (cf. Müller/Fürstenberg 2023; Krammer/Leichtfried 2024; Rezat/Schindler 2025) where teachers find ideas for lesson planning at different levels, get inspirations about different tools and understand the potential and thread AI can pose in educational contexts. Most of the examples are addressed to learners in secondary schools (but see Grundschule 2025).
When it comes to writing, one of the main focal points in the discussion is prompting as a new writing competence. Prompting refers to the act of writing (or dictating) an input to the AI, which is then used to create an output, ideally the expected output. To achieve that, different prompting strategies and types of prompts are discussed (cf. Knopp/Schindler 2025).
We distinguish between:
• Zero Shot-Prompts are prompts that do not use a lot of information. These prompts are considered rather simple when it comes to the inputs, the output is often not that precise. They correspond to a specific type of google request (e.g. How tall is the tallest person on earth?).
• In addition to the request, One Shot-Prompts also consist of an example (e.g. Can you give me a recipe for a French dish that is as famous as Mousse au Chocolat?).
• Few Shot-Prompts have more than one example.
• In Chained Prompting the inputs are concatenated with each other, the outputs are picked up accordingly and processed further as in the following example:
• Write an article about koalas in Australia. First give me the outline, which consists of a headline, a teaser and several subheadings. [Output]
• Now write five key messages for each subheading. [Output]
• Add five keywords to the core messages for each subheading. [Output]
• The so-called megaprompt (presented by Rob Lennon on Platform X in 2023) is particularly complex. A megaprompt provides information on the question of who or what is being simulated. It explains the task or activity (what is to be done?), provides information about the steps that need to be completed in sequence, formulates the conditions under which processing is to take place (these can also be restrictions), formulates the objective and the format of the output. In 2024, the megaprompt was considered rather effective for qualitative output. For the newer models in 2025 megaprompts are discouraged and disparaged as a boomer prompt10F[11]
Nevertheless, prompting is still discussed as a teachable skill in school (cf. Rezat/Schindler 2025). Whether this will remain relevant for long is unclear, as newer technologies support other ways of prompting and also certain apps were developed to support the prompting skills. Despite its pedagogical approach, prompting can also be interesting when it comes to researching writing skills: How do writers interact with an AI via prompt, what types of prompts do they compose and potentially revise, how closely are input (prompt), output (generation) and text linked?
3 Writing a Fairy Tale with AI
To understand whether and how primary school pupils use AI, we conducted a study in a primary school. It took place in a municipal primary school in Wuppertal, a medium-sized town (approximately 360.000 habitants) in the east of North-Rhine Westphalia. The two-track primary school comprises eight classes (two for each grade) and is classified with a three (out of nine) in the school social index.11F[12]
3.1 The Writing Assignment
The study was conducted in the summer of 2024 in a double lesson of 90 minutes with one class of fourth graders (see also Kutzner/Schindler 2025). One of the authors worked as a pedagogical support staff member at the school and led the so-called tablet club, so she was already known by the pupils. 24 pupils were present. The lesson consisted of two parts. During the first part, the study design was explained, the writing task – to write its own fairy tale – described and the work organised (the platform fobizz, which is widely known in school contexts, was used so the pupils didn’t need to register or identify themselves, instead they receive a code to gain access to GPT-4o). During the second part, the pupils worked in groups of two writing their fairy tale. The lesson was terminated by a short evaluation.
Fairy tales are an important genre in primary school and part of the curriculum, mostly in third and fifth grade (see Praxis Deutsch 284/2020). The pupils are therefore well aware of the main characteristics of fairy tales and know literary examples (mostly of the Brothers Grimm). They read fairy tales in school but most of them haven’t written their own fairy tale yet. The lesson therefore started out by reminding the pupils about the key elements which were also written on the assignment sheet that was handed out to the pupils:

Figure 1: Key Features of Fairy Tales (reflecting didactic customs in this area12F[13]
The setting consisted of two iPads for a pair of two pupils. On one of the iPads, GPT-4o was open, on the other one, a text editor was already put into operation. The idea of having two iPads with different functions was that the pupils thereby weren’t able to copy and paste the output generated by GPT-4o as easily but instead have to discuss and adapt it for their own text.
Since most of the pupils weren’t familiar with using generative AI, the work was supported by a worksheet with some instructions about prompting.

Figure 2: Helpful prompts for writing a fairy tale with GPT-4o13F[14]
The assignment itself was as followed:

Figure 3: Writing Assignment14F[15]
By working together, the pupils experience a form of collaborative writing (cf. Lehnen 2015). Collaborative writing is not only very common in most professional contexts (cf. Schindler/Wolfe 2014), it is also used as a tool for learning writing (cf. Knopp/Schindler 2020) as the writers can benefit from the writing expertise of their counterpart.
We collected twelve texts and eleven chat protocols; one of the chat protocols for a text was lost, unfortunately.
|
Code / |
Title of the fairy tale
Number of words produced in the text editor |
Number of prompts produced Words produced in prompts in total |
|
ZG01 |
Der Fluch des unsichtbaren Schattens 163 words |
12 prompts 236 words |
|
ZG02 |
Der König, der zum Räuber wird 171 words |
13 prompts 78 words |
|
ZG03 |
Der Untergang von Lothlorien Amazon Prime 322 words |
5 prompts 77 words |
|
ZG04 |
Luna die Mond Fee 181 words |
13 prompts 110 words |
|
ZG05 |
Das Geheimnis des magischen Amuletts 55 words |
4 prompts 21 words |
|
ZG06 |
Das Geheimnis des Amuletts 89 words |
8 prompts 61 words |
|
ZG07 |
no title 32 words |
6 prompts 42 words |
|
ZG09 |
Mein Märchen 15 words |
10 prompts 64 words |
|
ZG11 |
Unser Märchen 65 words |
9 prompts 72 words |
|
ZG12 |
Der verfluchte Wald 62 words |
no chat protocol |
|
ZG13 |
Die kleine Fee und der verlorene Stern 120 words |
8 prompts 43 words |
|
ZG14 |
Mister Melone 109 words |
4 prompts 20 words |
|
total
|
12 texts 1384 words |
92 prompts 824 words |
Table 1: The Dataset
The type of data enables different research methods used in writing research (cf. Becker-Mrotzek/Grabowski/Steinhoff 2017; Brinkschulte/Kreitz 2017). As writing with an AI hasn’t been discussed in a broad sense with view to methodological questions in writing research (for methodological suggestions see Schneegaß 2025, for writing with digital writing tools Schneider/Anskeit 2017), we propose to use the methods used so far in a slightly different way, for that we will first establish an idea of the type of data – chat protocols.
A chat with an AI has similarities to (written) chats with humans (see also Beißwenger 2007), as it also consists of a form of interaction that is characterised by its sequentiality but it is faster, more accurate, and more addressee-oriented as chats between humans as the opposite is a well-trained machine. Up to now, the machine needs input – the prompts – to produce the (generated) output. One of our focal points is therefore directed toward the prompts users create. Prompts can consist of a single or multiple elements – it is only limited with regard to a so-called context window, which can vary with regard to the AI model. We therefore propose two types of analysis: First, a more accurate linguistic (syntactic, semantic and pragmatic) analysis of the prompts the writers produce; second, a linguistic analysis of the text written by the pupils. With regard to the prompts, we want to know how these are constructed and if we can find certain patterns of linguistic structures in them. By analysing the written texts, we try to assess the influence of the AI: Do the pupils’ texts mostly consist of the output GPT-4o produced or do the writers use their own words and expressions.
4 Results and Discussion
4.1 Prompt Procedures
Overall, 92 prompts and 824 words were produced. Concerning the entire scope of text production (written text and prompts in total), the prompts take up 37 %. With that said, the production of prompts is therefore not an insignificant part of the writing process.
To describe these prompts more accurately, we use the term prompt procedure by analogy to the well-established term text procedure (cf. Feilke/Rezat 2025). Text procedures have three main characteristics: Firstly, they link form (linguistic expression) with certain pragmatic actions (function) in texts. Secondly, they depend on the (type of) text and the context of writing and thirdly, they can offer insights (and support) into grammatical structures. By inventing this term, we try to describe the writing activities more closely.
4.1.1 Prompt Structure established by Predefined Settings
The analysis of user-generated prompts reveals a remarkably systematic structure with underlying natural language queries. By formalising these prompt procedures using a rule-based schema, we gain insight into how language users operationalise communicative functions such as commands, demands, requests, intentions, information-seeking acts or creative output from artificial interlocutors. This formalisation not only enhances the interpretability of the prompts but also facilitates their functional classification based on syntactic and pragmatic features.
In order to establish the underlying schema, we shall first take a look at the prompts provided in the assignment sheet handed out to the pupils, as they serve as reference points for the identification of structural patterns and the subsequent abstraction into reusable templates:
1. I am a primary school pupil in year 4.
2. I want to write a fairy tale. Can you give me 3 ideas for the characters / plot / setting?
3. Can you give me 5 other words for ...?
The first proposed prompt expresses a self-ascriptive statement, in which the subject I is in a specific state: am an elementary school pupil in year 4. The utterance does not constitute a request per se but rather functions as a contextualisation of speaker identity. It can thus be formalised as:
4.
I am a primary school pupil in year 4.
[subject] + [state]
The second proposed prompt consists of a compound construction, combining an explicit statement of intention with a subsequent interrogative request. In the first clause, the subject expresses the intention to write a fairy tale. This is followed by a polar interrogative that addresses the addressee (here: the language model) and requests the generation of content, thereby making the addressee the recipient of the object in question. In this context, the modal verb can functions as an interrogative operator, indicating the polarity of the request (i. e. a yes-no question). Thus, it can be formalised like so:
5.
I want to write a fairy tale.
[subject] + [intention] + [object]
Can you give me 3 ideas for the characters / plot / setting?
[question] [[INT.y/n.operator] + [addressee] + [recipient] + [amount3] +
[object] for [object]]
The third example follows a structurally similar interrogative pattern to the second clause of the previous prompt; however, in this case, the requested object (i.e. other words) is further specified by a condition, namely the target lexical item (a semantic or lexical field) indicated by the ellipsis (“...”). A formalised pattern would therefore be:
6.
Can you give me 5 other words for ...?
[INT.y/n.operator] + [addressee] + [recipient] + [amount] + [[object] +
[condition]]
This prompt introduces a lexical or semantic constraint on the object to be generated and is typically used in tasks requiring lexical variation, rephrasing, or vocabulary expansion. The condition component plays a central role in narrowing the generative scope of the model’s output. In our data, pupils used this structure, for example, to request alternatives for common connectors or verbs such as then or went.
4.1.2 Prompt Procedures developed by the Writers
At first glance, one might assume that providing an assignment sheet with these proposed prompts would constrain the structural variety of pupil-generated inputs; however, the data15F[16] reveals quite the opposite. Of the total 92 prompts, only a small number mirror the structures of the proposed examples. Specifically, just 5 prompts (5.43 %) follow the structure of Prompt 1, 5 prompts (5.43 %) correspond to the first sentence of Prompt 2, and 7 prompts (7.61 %) resemble the second sentence of Prompt 2. Notably, none replicate the structure of Prompt 3.
Instead, our data shows that the vast majority of prompts exhibit a high degree of structural autonomy not displayed in the proposed prompts and can be categorised into three primary procedural types, here referred to as prompt procedures. Each of these is characterised by a distinct communicative function and syntactic pattern:
•
Imperative requests
(e.g. Tell me 15 fairy tale characters)
•
Interrogative polar (yes-no) questions
(e.g. Do you have an idea for a fairy tale?)
•
Interrogative wh-questions
(e.g. What do these characters experience?).
In addition to these dominant types, a smaller subset of prompts diverges from the main structural patterns and requires separate treatment. These exceptional cases can be subsumed under three further categories:
•
Statements of identity and intention
(similar to the proposed prompts, e.g. I am a 4th
grade primary school student)
•
Reduced and elliptical forms
(e.g. more)
•
narrative introductions
(e.g. ChatGPT we have a horror fairy tale here and want to know what happens
next. Here is the text. Once upon a time [...]).
Imperative requests represent the most frequently observed prompt procedure within the dataset. These prompts are typically formulated as direct commands instructing the language model to produce specific items – such as names, places, headlines, or narrative elements – and reflect a pragmatic orientation toward goal-directed language use. Their basic structure adheres to the following schema:
[IMP.operatorX] + [recipientX] + [amountX] + [object]
An illustrative example of this type is the prompt:
7. Tell me 15 fairy tale characters. (ZG02)
[IMP.operator1] + [recipient1]16F[17] + [amount15] + [object]
This base structure can be flexibly extended to comprise additional parameters, enabling users to narrow or refine the semantic scope of their request. One common extension involves the specification of an object in relation to a genre or narrative frame, as in:
8.
Tell me three places for a fairy tale. (ZG04)
[IMP.operator1] + [recipient1] + [amount3] + [object] for
[object]
Another frequent variation involves a marker for a possession which personalises the requested content:
9.
Tell me 10 characters for my fairy tale. (ZG07)
[IMP.operator1] + [recipient1] + [amount10] + [object]
for [[possession1]17F[18] + [object]]
Similarly, prompts may include conditions that constrain the semantic field of the generated items:
10. Tell me ten headlines for a story with a curse. (ZG01)
[IMP.operator1] + [recipient1] + [amount10] + [object] for [[object] with
[condition]]
Further structural complexity arises in prompts that incorporate modifiers, such as character traits, features for objects or qualitative requirements, which enable a higher degree of specificity. Examples include:
11. Tell me evil characters. (ZG04)
[IMP.operator1] + [recipient1] + [trait] + [object]]
12.
Tell me three imaginary places. (ZG06)
[IMP.operator1] + [recipient1] + [amount3] + [[feature] +
[object]]
13.
Tell me ten perfect headlines for my cursed
fairy tale. (ZG01)
[IMP.operator1] + [recipient1] + [amount10] + [[quality] + [object]] for
[[possession1] + [feature] + [object]].
The syntactic structure of these prompts follows a relatively stable pattern, which facilitates a controlled generation of language output by explicitly encoding both quantity (e.g. three, five, ten) and semantic scope (e.g. characters, names, headlines). The imperative request procedure was observed in 52 of 92 analysed prompts, accounting for 56.52 % of the dataset. Within this category, the operator tell (mapped as [IMP.operator1]) proved to be the most frequently used lexical realisation, indicating a preference for direct, instructional formulations that clearly define both the speaker’s intention and the desired output. Other lexical realisations such as say and give appear less frequently but serve a similar directive function:
|
Operator |
Lexical realisation |
Frequency |
|
[IMP.operator1] |
tell |
46 |
|
[IMP.operator2] |
say |
4 |
|
[IMP.operator3] |
give |
2 |
|
total |
52 |
|
Table 2: Distribution of the [IMP.operator]
Interrogative polar (yes–no) questions function as binary inquiries that aim to elicit either confirmation or negation from the addressee. In the context of human–AI interaction, such prompts are frequently used to assess the model’s capabilities, knowledge, or willingness to assist with a given task. Syntactically, these questions typically take the form of auxiliary-initial constructions (e.g. “Do you have...?”, “Can you tell...?”) and can be formally represented by the following schema:
[INT.y/n.operatorX] + [addressee] + [object]
An example illustrating this procedure is:
14. Do you have an idea for a fairy tale? (ZG04)
[INT.y/n.operator1] + [addressee] + [object] for [object].
This basic structure can be further modified by optional elements to enhance specificity or complexity. One common extension involves the inclusion of qualitative modifiers:
15. Do you have an idea for a really good fairy tale? (ZG11)
[INT.y/n.operator1] + [addressee] + [object] for [[quality] + [object]]
Another variant incorporates conditions or scenario-based constraints into the requested content:
16. Do you have a good idea
[INT.y/n.operator1] + [addressee] + [[quality] + [object]]
for a good fairy tale with a princess and a wizard and a knight?
for [[quality] + [object] with [condition]]
(ZG04)
These polar interrogatives serve not only as requests for information but also as implicit directives, as they often anticipate that the model will provide a concrete response output rather than a mere affirmation or denial. As such, they occupy a hybrid position between epistemic inquiry and goal-directed instruction. However, the example above can also be seen as an instance of positive politeness (Brown & Levinson 1987). By implying that the addressee might have a good idea, the speaker acknowledges their competence and creativity, thereby attending to their positive face. Even without explicit politeness markers such as please or inclusive pronouns like let’s, the utterance creates a collaborative and affiliative tone by inviting the interlocutor to contribute creatively. In the dataset, this yes-no prompt procedure was used a total of 14 times (15.22 %), making it the second most frequent structural category after the imperative request procedure. A lexical analysis of the operators used within these prompts reveals a clear preference for do [...] have and can [...] tell as initiating verbs:
|
Operator |
Lexical realisation |
Frequency |
|
[INT.y/n.operator1] |
do [...] have |
4 |
|
[INT.y/n.operator2] |
do [...] know |
1 |
|
[INT.y/n.operator3] |
can [...] tell |
4 |
|
[INT.y/n.operator4] |
can [...] help |
2 |
|
[INT.y/n.operator5] |
can [...] show |
2 |
|
[INT.y/n.operator6] |
can [...] give |
1 |
|
total |
14 |
|
Table 3: Distribution of the [INT.y/n.operator]
The usage of these interrogative forms points to an inclination toward politeness and cooperative discourse strategies: Rather than issuing direct commands, these users frame their requests as questions – a linguistic strategy that aligns with social conventions of human interaction.
Interrogative wh-questions represent a distinct type characterised by their open-ended structure and their function in eliciting information. Unlike yes–no questions, which solicit binary responses, wh-questions aim to open a semantic space in which the respondent (here: the language model) is expected to generate information that is not already presupposed in the question. Syntactically, these prompts begin with an interrogative word (wh-word), such as what, where, how, or which, typically followed by a verb phrase – here formalised as an operator – that frames the focus of the request:
[wh-question word] + [INT.wh.operatorX] + [object]
This can further be illustrated with the following example:
17. What do these characters experience? (ZG09)
[wh-question word] + [INT.wh.operator7] + [object]
Overall, the wh-prompt procedure was used 10 times (10.87 %). Notably, each identified wh-prompt procedure was instantiated exactly once, indicating a high degree of lexical and functional diversity within this category. The variety of operators suggests that users employ wh-prompt procedures across a wide range of conceptual domains: From naming characters and character behaviour to settings and language:
|
Operator |
Lexical realisation |
Frequency |
|
[INT.wh.operator1] |
can [...] call |
1 |
|
[INT.wh.operator2] |
can [...] be called |
1 |
|
[INT.wh.operator3] |
can [...] become |
1 |
|
[INT.wh.operator4] |
appear |
1 |
|
[INT.wh.operator5] |
rhymes |
1 |
|
[INT.wh.operator6] |
is [...] called |
1 |
|
[INT.wh.operator7] |
do [...] experience |
1 |
|
[INT.wh.operator8] |
is [...] set |
1 |
|
[INT.wh.operator9] |
are |
1 |
|
[INT.wh.operator10] |
old |
1 |
|
total |
10 |
|
Table 4: Distribution of the [INT.wh.operator]
This broad spectrum of wh-prompt procedures reflects the flexibility of users, who formulate prompts not merely as procedural commands but as genuine epistemic inquiries into the narrative structure of their creative tasks. Although the absolute frequency of these procedures is lower than that of imperative or yes–no procedures, their functional richness and structural variability suggest a high degree of expressive potential.
As shown in the table below, a clear majority of the prompts can be accounted for by one of these three operator types. Most prominent among them are imperative prompts ([IMP.operatorX]), which constitute more than half of all prompts in the dataset. This predominance reflects a strong tendency among users to formulate their input in the imperative mood, clearly instructing the model to perform a task. Yes-no questions ([INT.y/n.operatorX]) represent the second most frequent category, reflecting a communicative strategy that seeks confirmation, permission, or availability. Wh-questions are used less frequently ([INT.wh.operatorX]), but they play a distinct role in eliciting information or conceptualisations. The remaining 17.39 % of prompts in the dataset fall outside these core categories and are addressed separately under more exceptional structural types.
|
Operator classification |
Frequency |
% of overall prompts |
|
[IMP.operatorX] |
52 |
56.52 % |
|
[INT.y/n.operatorX] |
14 |
15.22 % |
|
[INT.wh.OperatorX] |
10 |
10.87 % |
|
total |
76 |
82.61 % |
Table 5: Distribution of all operators
Imperative requests, formulated in the imperative mood, as well as Interrogative polar (yes–no) questions and interrogative wh-questions, formulated in the interrogative mood, can be classified as instances of directive illocutionary speech acts (cf. Searle 1975). These speech acts are characterised by the speaker’s intention to prompt the addressee – in this case, the language model – to carry out a specific action; here, the generation of content. While differing in surface structure and modality, these prompt types share a common illocutionary force, namely the attempt to direct the interlocutor’s behaviour toward a clearly formulated communicative goal.
The category of statements of identity and intention constitutes the first of three structural categories that can be classified as exceptional cases, insofar as these prompts deviate from the dominant patterns of imperative or interrogative prompting procedures and occur only sporadically. These procedures appear to serve primarily as meta-linguistic framing devices as they introduce either the personal state or the narrative intention of the speaker, often paired with a subsequent request directed at the model. Rather than directly generating content, these procedures contextualise the speaker’s position, either socially (e.g. as a young learner) or communicatively (e.g. as someone about to request creative support). In this way, they serve as discourse scaffolding for the actual prompt that follows, aiming to increase the relevance or appropriateness of the model’s output.
In the analysed dataset, six instances (6.52 %) explicitly refer to the state or identity of the prompter. Of these, five follow the schema established for the proposed prompts and can be captured by a pattern such as:
[subjectX] + [state]
An example of this procedure in the dataset is:
18. I am a 4th grade primary school student. (ZG09)
[subject1]18F[19] + [state]
In addition, five further prompts involve an explicit statement of intention, usually embedded within a compound structure that culminates in a subsequent request. These follow a more complex pattern such as:
19. I want to write a fairy tale can you give me 3 ideas for the
characters? (ZG06)
[subject1] + [intention] + [object] + [question]
[[INT.y/n.operator6] + [addressee] + [recipient1] +
[amount3] + [object] + [object]]
These combinations reveal how users shape AI-interactions by contextualising their prompts within a personal or narrative frame to elicit more relevant responses. Although infrequent, these meta-linguistic constructions are functionally significant, as they provide insight into the discursive strategies users employ to manage interaction with an artificial agent.
A small, yet noteworthy, subset of prompts in the dataset consists of utterances with minimal lexical material. These prompts can be classified as reduced and elliptical forms, as they omit elements that would typically be required for a syntactically complete sentence. Despite their brevity, such prompts are highly functional and intelligible within their respective discourse contexts. They frequently exploit the coherence of the discourse situation to economise the linguistic effort. Their interpretation relies on contextual embedding, often drawing from a preceding prompt or from a shared understanding of the interactional task. Therefore, these prompts tend to occur not as initial entries, but rather as follow-up prompts. Examples from the dataset illustrate this pattern:
20.
More (ZG01)
[quantity modifier]
21.
New characters (ZG13)
[alternative] + [object]
22.
Names for dragons (ZG09)
[object] for [object]
In all these instances, the imperative or interrogative operator is omitted, yet the intended meaning is recoverable from the respective context. From a structural perspective, these forms challenge syntactic structures, yet they are pragmatically rich and often semantically unambiguous. Their occurrence highlights the flexibility and adaptability of user strategies in prompt construction, particularly within human-AI dialogue, where a tendency toward conversational economy emerges: Once mutual understanding has been established, users often shift toward minimal and efficient language formats, deviating from the conventions of typical human-human interaction.
Unique within the dataset is the structure of narrative introduction. This form embeds an extended narrative fragment within the prompt itself and pairs it with an explicit continuation request directed at the model. Unlike other prompts that ask for lists, names, or information in a concise format, narrative introductions unfold over several sentences and serve a dual function: They present a story framework and simultaneously solicit a generative response that continues or completes the narrative:
23. ChatGPT we have a horror fairy tale here and want to know what
happens next. Here is the text. Once upon a time [...] (ZG01)
[addressee] + [subject2] + [situation] + [desire] + [narrative]
This prompt begins by directly addressing the model (e.g. ChatGPT), followed by a brief metatextual statement that describes the situation. The users indicate that they already have a narrative fragment and express their desire for continuation. This is followed by the narrative itself.
The interplay between metatextual framing and narrative content makes this prompt procedure as particularly rich in terms of linguistic structure and communicative layering. It simulates natural storytelling practices and reflects a shift from transactional interaction to collaborative narrative co-construction. Moreover, these procedures suggest a higher degree of user engagement and planning, as the narrative portion is typically composed in advance and intentionally handed over to the model for creative expansion, thus exemplifying the potential of generative systems to act not merely as tools but as collaborative partners in creative processes.
Another central component in the formal categorisation of prompt procedures is the analysis of personal pronouns. Several types of referential functions can be identified and systematically classified through markers for subjects, recipients, possessives, and addressees. A particularly striking feature is the frequent use of first-person singular pronouns in the dataset, especially I, me, or my, which dominates both subject and recipient roles (78 prompts in total / 84.78 %). This tendency can be traced back to the proposed prompts provided in the assignment sheet, many of which were formulated in the first person (e.g. I am a primary school student…, I want to write a fairy tale…, Can you give me…). As a result, many pupils appear to have adopted this self-referential structure directly, resulting in a noticeable pattern of I-centred formulations, despite the fact that they were working in pairs of two. The distribution of personal reference markers in the dataset is as follows:
|
Reference marker |
Lexical realisation |
Frequency |
|
[subject1] |
I |
8 |
|
[subject2] |
we |
3 |
|
total |
11 |
|
|
[recipient1] |
me |
57 |
|
[recipient2] |
us |
3 |
|
total |
60 |
|
|
[possession1] |
my |
13 |
|
[possession2] |
our |
1 |
|
total |
14 |
|
|
[addressee] |
you (i.e. ChatGPT) |
14 |
|
overall total |
99 |
|
Table 6: Distribution of reference markers
These figures indicate a clear preference for an individual perspective in prompt procedures. Collective reference using we, us, or our is significantly less frequent, which may reflect the fact that many prompts were phrased individually, or that users identified more strongly with their own personal voice. The high frequency of my also suggests a tendency to personalise the content and explicitly claim the ownership of the narrative, referring to my fairy tale or my story.
In light of findings from conversation analysis, several deviations from typical human-human interactional norms can be observed in the dataset. While the prompts clearly function as communicative acts, they often lack features associated with ordinary face-to-face conversation, particularly at the level of interactional framing. Elements such as greetings, expressions of politeness, or inquiries about well-being, which serve important social and relational functions in natural discourse, are either entirely absent or occur only very marginally.
For instance, greetings, which typically initiate conversational exchanges in human interaction, appear in only three prompts (3.26 %) across the dataset. Similarly, explicit politeness markers, such as please, are nearly absent, occurring only once (1.09 %) in the entire corpus. Likewise, emphatic expressions which serve to establish or maintain interpersonal contact rather than convey propositional content are extremely rare. Only one prompt (1.09 %) contains a question about the model’s well-being, which is a prototypical opening in casual human conversation; however, in this user group’s interaction, it was the very last prompt. The interactional norms are formally marked and distributed as follows:
|
Interactional element |
Lexical |
Frequency |
% in this category |
% of overall prompts |
|
[greeting] |
Hello |
3 |
60.00 % |
3.26 % |
|
[politeness] |
please |
1 |
20.00 % |
1.09 % |
|
question about state of well-being |
How are you |
1 |
20.00 % |
1.09 % |
|
total |
5 |
100.00 % |
5.43 % |
|
Table 7: Distribution of interactional elements
The limited use of greeting formulas and other phatic elements highlights the task-oriented nature of the interaction: users focus primarily on content generation and often omit social routines that typically frame human-human conversation. This does not necessarily indicate a communicative deficit. Rather, it may reflect that pupils are addressing an artefact rather than a human interlocutor and therefore orient to the interaction as an instrumental, instruction-based exchange. Instead of greetings or pleasantries, communication is frequently initiated through direct content requests, such as:
24. Tell me 15 characters. (ZG02)19F[20]
[IMP.operator1] + [recipient1] + [amount15] + [object]
in initial prompts or simply:
25. more (ZG01)
[quantity modifier]
in follow-up prompts.
Interestingly, the interactional elements were only used by three of the eleven pupil pairs:
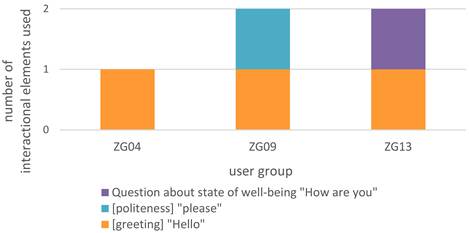
Figure 4: Interactional elements used by user groups
This limited distribution suggests that the majority of pupils engaged with the language model in a predominantly task-oriented manner, ignoring the social conventions typically associated with human-human communication. The few instances in which such elements were included appear to be the result of individual stylistic choices rather than class-wide strategies and may reflect a greater degree of social framing or anthropomorphisation of the model on the part of those specific users. This selective use suggests a fundamental reconfiguration of conversational norms in the context of human-AI interaction: functional efficiency and goal-orientation are prioritised over interpersonal ritual. While the sporadic appearance of conventional interactional elements, such as greetings and politeness, indicates that users do, at times, engage with the AI as a social actor, albeit selectively, this hybridity points to the evolving nature of digital dialogue and raises questions about the extent to which social norms are transferred, adapted, or suspended in interactions with artificial interlocutors.
Several prompts in the dataset contain evaluative, characterising, or descriptive elements that serve to specify or constrain the nature of the requested output. These elements, which we categorise under the umbrella of qualitative modifiers, enrich the prompts by adding semantic depth and help to guide the AI toward responses that meet specific expectations of content type. They can be further subdivided into three distinct types based on their semantic function within the prompt:
•
[quality]: general evaluative adjectives
(e.g. good, really good, perfect)
•
[trait]: character-related attributes
(e.g. extraordinary, evil)
•
[feature]: content-specific or contextual descriptors
(e.g. cursed, beautiful, imaginary, mysterious, small)
|
Qualitative modifier |
Lexical realisation |
Frequency |
|
[quality] |
good |
4 |
|
perfect |
2 |
|
|
really good |
1 |
|
|
total |
7 |
|
|
[feature] |
beautiful |
3 |
|
cursed |
2 |
|
|
imaginary |
1 |
|
|
mysterious |
1 |
|
|
small |
1 |
|
|
very small |
1 |
|
|
exciting |
1 |
|
|
total |
10 |
|
|
[trait] |
extraordinary |
4 |
|
evil |
1 |
|
|
total |
5 |
|
|
total |
22 |
|
Table 8: Distribution of qualitative modifiers
Similar to the interactional elements, these qualitative modifiers were employed by only a small number of pupil pairs:
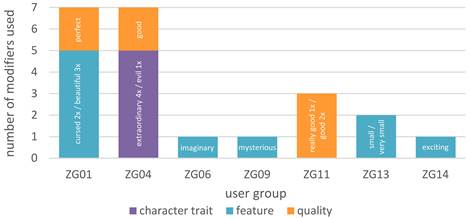
Figure 5: Qualitative modifiers used by user groups
Despite their high potential for enriching prompt specificity and enabling fine-grained control over content generation, these linguistic resources were not widely used across the dataset. Instead, their presence appears to be concentrated within just a few user groups, suggesting that only certain pupils engaged with the language model in ways that went beyond basic requests. This selective use of modifiers points to a broader pattern: While all groups successfully issued functional prompts, only a minority actively shaped the tone, quality, or thematic orientation of the generated content through linguistic refinement. Just as interactional elements such as greetings or politeness were used only sporadically, qualitative modifiers were likewise not integrated into the majority’s prompt repertoire. Their distribution reflects notable variation in prompt procedures, with most prompts remaining minimal or structurally formulaic, and only a few showing evidence of intentional stylistic or semantic modulation. Nonetheless, the prompts that do include such modifiers demonstrate the powerful affordances of descriptive language in AI-assisted creative tasks. These few pupil pairs were able to exert greater narrative control, evoking specific genres, moods, or character roles. The fact that such modifiers were only used by select groups may indicate differences in linguistic competence, genre familiarity, or awareness of the model’s responsiveness to nuance. It also raises pedagogical questions about how learners conceptualise the interaction: primarily as a tool-based retrieval task or as a dialogic, co-creative process.
In this sense, the rarity of qualitative modifiers and interactional elements can be interpreted as a window into emerging patterns of prompt literacy: While some users begin to explore and test the expressive potential of language, others rely on more minimal and procedural forms of communication, particularly in early stages of engagement with generative systems.
A comparison of the two graphs (interactional elements vs. qualitative modifiers) reveals three user groups that stand out: ZG04, ZG09, and ZG13. These groups are notable in that they contributed both interactional elements and qualitative modifiers, distinguishing themselves from the remaining groups, which either used neither or only one of the two:
|
User group |
Number of |
% in this |
Number of |
% in this |
Number |
% of both |
|
ZG04 |
1 |
20 % |
7 |
31.82 % |
8 |
29.63 % |
|
ZG09 |
2 |
40 % |
1 |
4.55 % |
3 |
11.11 % |
|
ZG13 |
2 |
40 % |
2 |
9.09 % |
4 |
14.81 % |
|
total |
5 |
100 % |
22 |
100 % |
27 |
100 % |
Table 9: Comparison of interactional elements and qualitative modifiers usage
ZG04 accounts for 20 % of all interactional elements and 31.82 % of all qualitative modifiers, making up nearly 30 % of both categories combined. ZG09 contributed 40 % of all interactional elements, though only 4.55 % of all modifiers, indicating an emphasis on conversational framing but less engagement with content refinement. ZG13 contributed 40 % of all interactional elements and 9.09 % of all modifiers, together making up nearly 15 % of both categories combined.
These findings imply that those pupils who are incorporating socially or stylistically enriched language in their prompts do so consistently and with an apparent sense of narrative or communicative intention. The fact that three out of eleven groups account for the vast majority of these linguistically rich prompts suggests that prompt literacy is yet unevenly distributed and possibly influenced by factors such as linguistic and genre awareness, communicative competence, or collaborative dynamics within the group.
Another prominent structural feature of many prompts in the dataset is the inclusion of explicit numerical values, which serve to define the desired quantity of output, for example, a specific number of names, characters, places, or ideas to be generated by the model. These quantity expressions, formally annotated as [amountX], play a key role in constraining and directing the model’s generative output.
The most frequently used number is three, appearing in 17 prompts. This prevalence is likely due to its presence in the proposed prompt examples included on the assignment sheet (e.g. Can you give me 3 ideas for the characters / plot / setting?) but may be also justified by the genre, as three is a very common number in fairy tales. The frequent recurrence of 3 thus reflects both the didactic framing of the task and the accessibility of the number as a cognitively manageable list size for young learners. In addition to 3, the numbers 5 and 10 were favoured by pupils, representing a balance between brevity and richness in content generation. While lower numbers dominate the distribution, the dataset also contains a number of outlier values, including significantly higher quantities such as 15, 35, 50, and even 5999, 10000, and 599999. These unusually high values likely indicate either playful experimentation or attempts to test the model’s generative limits, suggesting that some users engaged with the model in more exploratory or humorous ways. The full distribution of quantity expressions is summarised below:
|
Formal category |
Surface form |
Frequency |
|
[amount1] |
1 |
3 |
|
[amount2] |
2 |
4 |
|
[amount3] |
3 |
17 |
|
[amount4] |
4 |
2 |
|
[amount5] |
5 |
8 |
|
[amount10] |
10 |
10 |
|
[amount15] |
15 |
2 |
|
[amount35] |
35 |
2 |
|
[amount50] |
50 |
1 |
|
[amount100] |
100 |
1 |
|
[amount199] |
199 |
1 |
|
[amount5999] |
5999 |
1 |
|
[amount10000] |
10000 |
1 |
|
[amount599999] |
599999 |
1 |
|
total |
54 |
|
Table 10: Distribution of quantitative expressions
In summary, while most prompts employ low, “pedagogically appropriate” numbers, a small subset ventures into exaggerated or extreme quantities, providing insight into users’ willingness and eagerness to manipulate and play with the affordances of the artificial interlocutor.
4.2 Texts
Let us now take a step further and shift our analytical perspective from the structure of the prompts to the texts that emerged from them. This transition allows us to examine how AI-generated material was not only received but appropriated and woven into the pupils’ creative writing. The following analysis will be conducted in an exemplary fashion, focusing on selected cases only, as a comprehensive textual analysis of all submissions lies beyond the scope of this study. Nevertheless, the case studies presented here provide valuable insights into the ways in which pupils engaged with, transformed, or directly adopted AI-generated language into their creative narrative products.
The examples of pupil groups ZG01 and ZG04 offer two contrasting yet instructive examples of how generative AI content can be appropriated within creative writing processes. By examining the nature and extent of incorporation, we observe differentiating forms of engagement that range from selective to substantial adaptations of AI-generated elements. In order to categorise these patterns, four types of uptake are distinguished:
• complete adoption without modification,
• complete adoption with modifications,
• partial adoption without modification, and
• partial adoption with modifications.
The text produced by ZG01 demonstrates a highly targeted and selective use of AI-generated content. The title of their fairy tale, Der Fluch des unsichtbaren Schattens (‘The Curse of the Invisible Shadow’), was taken verbatim from a pool of 40 generated headlines, thus constituting a partial adoption without modification. Similarly, the character name Aurora was selected from a set of 24 generated names and incorporated without any alteration – again, a partial adoption without modification. However, the second protagonist, Lina, was not amongst the generated names and thus appears to have been independently created by the pupils. Aside from the headline and the character name, the narrative itself was entirely and independently authored by the pupils. In a final prompt requesting GPT-4o to continue and finish their story – likely due to time constraints – they submitted their own text to the model. This whole approach of ZG01 demonstrates a clear differentiation between using the model for inspiration and integrating its output directly.
The writing of ZG04 reflects a more integrative and generative engagement with AI content. Three characters from various AI-generated lists were used: Luna, Rufus, and Aurelia. The names and accompanying character descriptions of Luna and Rufus were derived from a pool of 27 characters in total and were incorporated into the pupils’ story with minor grammatical and stylistic modifications, such as tense shifts or word substitutions. Accordingly, these uses are best classified as partial adoptions with modifications. In the case of Aurelia, however, the character description was integrated in full and without any modification, marking a clear instance of complete adoption without modification. Additionally, the setting of the fairy tale – an enchanted forest (verzauberter Wald) – was selected directly from a list of eight suggested locations, representing another partial adoption without modification. Like ZG01, the pupils of ZG04 built their original story around the AI-suggested figures, integrating them into their own plot while preserving core descriptive elements from the prompts.
|
User group |
Element type |
GPT-4o output |
Pupil text excerpt |
Category |
Notes |
|
ZG01 |
title |
Der Fluch des unsichtbaren Schattens |
Der Fluch des unsichtbaren Schattens |
Partial adoption without modification |
Selected from list of 40 generated titles |
|
ZG01 |
character name |
Aurora |
Aurora |
Partial adoption without modification |
Selected from list of 24 generated names |
|
ZG04 |
character: Luna |
eine zarte Fee mit silbernen Flügeln, die nachts im Mondlicht tanzt und magische Träume bringt... |
eine zarte Fee mit silbernen Flügeln, die nachts im Mondlicht tanzte und magische Träume bringt... |
Partial adoption with modification |
Tense change |
|
ZG04 |
character: Rufus |
ein freundlicher Drache, der die Fähigkeit hat, mit Menschen zu sprechen. Er ist weise... |
ein freundlicher Drache und hat die Fähigkeit, mit Menschen zu sprechen. Er ist weise... |
Partial adoption with modification |
Slight rephrasing |
|
ZG04 |
character: Aurelia |
ein geheimnisvolles Wesen, das tief im Herzen eines uralten Waldes lebt... |
ein geheimnisvolles Wesen, das tief im Herzen eines uralten Waldes lebt... |
Complete adoption without modification |
|
|
ZG04 |
setting |
Der Verzauberte Wald |
Der Verzauberte Wald |
Partial adoption without modification |
Selected from list of 8 generated settings |
Table 11: AI-generated content in the texts
Together, these two cases illustrate two common strategies of prompt integration: selective uptake for titles or names without modification and autonomous narrative development (ZG01), and adaptive integration with slight transformation of AI-generated content (ZG04). Both reflect intentional engagement with the language model.
5 Conclusion
At the beginning of this article, we posed the following question: Can (and should) primary school pupils use AI technology for writing? Based on our findings, we argue that they can and that AI-supported writing can be a meaningful part of classroom practice. As long as generative AI tools rely on verbal or written input, their use inherently involves writing-related activity. The text production in a narrower sense does not necessarily benefit from it immediately as pupils may be distracted by the interface and need time to learn how to formulate prompts that lead to relevant output. As our analyses show, prompting is a complex process that can involve multiple writing-related activities, including planning, lexical searching, and reformulating. Against this background, we suggest that prompting strategies should not be left to incidental trial-and-error, but should be explicitly taught and systematically reflected in writing instruction (see also Desmond/Brachmann 2024).
The rule-based formalism – e.g. [X.operatorX] + [recipientX] + [amountX] + [object] – enables a systematic framework for encoding the underlying intentions of prompts across a wide range of natural utterances. These abstractions reveal common patterns involved in creative prompting, such as quantifying requests, specifying conditions, or foregrounding object traits, thus offering valuable scaffolding for tasks such as storytelling and creative writing, enabling more structured and intentional interactions with generative language models. The findings underscore the emergent regularity in human-AI prompting, even in non-expert populations such as children or young learners. Users naturally gravitate toward structurally consistent, semantically rich constructions that align with formal command syntax. This suggests that prompt literacy is not only teachable but perhaps already intuitive (at least for the generation of digital natives) – an important consideration for curricula that integrate AI-based tools.
To be effective in writing their prompts, the writers should focus on the intended output and the importance this output might have for their text. Some of the prompts give the impression that writers want to test the AI or just have fun trying it out. As is known for writing in general, writing with AI also needs writing strategies, e.g. concerning the text genre, the writing situation or the addressee (see also Sturm 2022). Writing pedagogy should therefore focus on teaching specific AI-related writing strategies and not suppress the usage of AI. In future educational implementations, such patterns could inform targeted instructional support, helping learners move beyond procedural input strategies toward more nuanced and intentional prompt construction – particularly when working with creative or narrative-oriented tasks.
References
Alles, Susanne/Falck, Joscha/Flick, Manuel/Schulz, Regina (2025): KI-Kompetenzen für Lehrende und Lernende. Aus der Praxis für die Praxis – eine adaptierbare Basis. In: VK:KIWA Blog.
Becker-Mrotzek, Michael/Grabowski, Joachim/Steinhoff, Torsten (ed.) (2017): Forschungshandbuch empirische Schreibdidaktik. Münster: Waxmann.
Beißwenger, Michael (2007): Sprachhandlungskoordination in der Chat-Kommunikation. Berlin: de Gruyter.
Brinkschulte, Melanie/Kreitz, David (ed.) (2017): Qualitative Methode in der Angewandten Schreibforschung. First edition. Bielefeld: wbv.
Brown, Penelope/Levinson, Stephen C. (1987): Politeness: Some Universals in Language Usage (Reissued with Corrections, new Introduction and new Bibliography). Cambridge: Cambridge UP.
Buck, Isabella/Limburg, Anika (2023): Hochschulbildung vor dem Hintergrund von Natural Language Processing (KI-Schreibtools). In: die hochschullehre (9).
DOI: 10.3278/HSL2306W
De Witt, Claudia/Gloerfeld, Christina/Wrede, Silke Elisabeth (ed.) (2023): Künstliche Intelligenz in der Bildung. Wiesbaden: Springer.
Doshi, Anil R./Hauser, Oliver (2024): Generative AI enhances individual creativity but reduces the collective diversity of novel content. In: Science Advances 10 (28).
Desmond, Michael/Brachman, Michelle (2024): Exploring Prompt Engineering Practices in the Enterprise. arXiv: 2403.08950.
DOI: 10.48550/arXiv.2403.08950
Emsley, Robin (2023): ChatGPT: these are not hallucinations – they’re fabrications and falsifications. In: Schizophrenia 9 (52).
DOI: 10.1038/s41537-023-00379-4
Feilke, Helmuth/Rezat, Sara (2025/to appear): Textprozeduren. Werkzeuge für den Schreibunterricht – Grundlagen und unterrichtspraktische Anregungen. Hannover: Klett/Kallmeyer.
Gredel, Eva/Pospiech, Ulrike/Schindler, Kirsten (2024): Künstliche Intelligenz und Schreiben in (hoch-)schulischen Kontexten. In: Zeitschrift für germanistische Linguistik 52 (2), 378–404.
Grundschule (2025): Künstliche Intelligenz und Schule. Westermann.
URL: https://www.westermann.de/artikel/53250200/Grundschule-Kuenstliche-Intelligenz-und-Schule
Hackl, Stefan (2025/in print): Impulse zur Professionalisierung der Vermittlung und Förderung von KI-Kompetenzen von (angehenden) Deutschlehrkräften. In: Leseräume (11).
Helm, Gerrit/Hesse, Florian (2025, to appear): Training writing programmes on writing with AI – but for whom? Identifying students’ writer profiles through two-step cluster analysis. In: Journal of Writing Research.
Helm, Gerrit/Hesse, Florian (2024): Usage and beliefs of student teachers towards artificial intelligence in writing. In: RISTAL (7), 1–19.
Knopp, Matthias/Schindler, Kirsten (2025): Schöne neue Textwelt – Vertrauen in KI generierte Texte. In: Emmersberger, Stefan/Kammerer, Ingo (ed.): Mediale Praktiken in einer Kultur der Digitalität – Impulse für sprachliche und literarische Bildung. Stuttgart: Metzler Verlag, 139-159.
Knopp, Matthias/Schindler, Kirsten (2020): Schreiben als multimodales und kooperatives Handeln im Medium der Schrift. In: Aebi, Adrian/Göldi, Susan/Weder, Mirjam (ed.): Schrift-Bild-Ton: Einblicke in Theorie und Praxis des multimodalen Schreibens. Bern: hep, 125–148.
Knoth, Nils/Tolzin, Antonia/Janson, Andreas/Leimeister, Jan Marco (2024): AI literacy and its implications for prompt engineering strategies. In: Computers and Education: Artificial Intelligence 6 (100225). DOI: 10.1016/j.caeai.2024.100225
Krammer, Stefan/Leichtfried, Matthias (2024): Zwischen Hype und Disruption. Künstliche Intelligenz im Deutschunterricht. In: Krammer, Stefan/Leichtfried, Matthias (ed.): Künstliche Intelligenz. ide (Informationen zur Deutschdidaktik 2) (48), 23–31.
Kutzner, Alyssa (2026): Schreiben von Zusammenfassungen unter Unterstützung von KI. In: ide (Informationen zur Deutschdidaktik) (4) (manuscript submitted)
Kutzner, Alyssa/Schindler, Kirsten (2025): Die KI schreibt mit – Viertklässler*innen formulieren Märchen mit Hilfe von ChatGPT. In: Grundschule (2), 17–21.
Lehnen, Katrin (2015): Schreiben als soziale Praxis. Herausforderungen und Methoden der gemeinsamen Arbeit an Texten. In: Deutsch 5 bis 10. Kooperatives Schreiben (44), 30–31.
Leiter, Christoph/Zhang, Ron/Chen, Youran/Belouadi, Jonas/Larionov, Daniil/Fresen, Vivian/Eger, Steffen (2024): ChatGPT: A meta-analysis after 2.5 months. In: Machine Learning with Applications (16).
DOI: 10.1016/j.mlwa.2024.100541
Malmström, Hans/Stöhr, Christian/Ou, Amy Wanyu (2023): Chatbots and other AI for learning: A survey of use and views among university students in Sweden. In: Chalmers Studies in Communication and Learning in Higher Education (1).
DOI: 10.17196/cls.csclhe/2023/01
Memarian, Bahar/Dolech, Tenzin (2023): ChatGPT in education: Methods, potentials and limitations. In: Computers in Human Behaviour: Artificial Humans 1 (2).
DOI: 10.1016/j.chbah.2023.100022
Müller, Hans-Georg/Fürstenberg, Maurice (2023): Der Sprachgebrauchsautomat. Die Funktionsweise von GPT und ihre Folgen für Germanistik und Deutschdidaktik. In: Mitteilungen des Deutschen Germanistenverbandes 4 (70), 327–345.
Niloy, Ahnaf Chowdhury/Akter, Salma/Sultana, Nayeema/Sultana, Jakia/Rahman, Sayed Imran Ur (2024): Is ChatGPT a menace for creative writing ability? An experiment. In: Journal of Computer Assisted Learning 40(2), 919–930.
Phan, Ti Ngoc Le (2023): Students’ Perceptions of the AI Technology Application in English Writing Classes. In: Proceedings of the AsiaCALL International Conference (4), 45–62.
DOI: 10.54855/paic.2344
Kammler, Clemens (2020): Märchen in Geschichte und Gegenwart. In: Praxis Deutsch 47 (284), 4–11.
Rezat, Sara/Schindler, Kirsten (2025/to appear): Texte lesen und schreiben mit KI. In: Praxis Deutsch (311).
Schindler, Kirsten (2024): ChatGPT oder Überlegungen zu den Veränderungen des Schreibens in der Schule. In: MiDU – Medien Im Deutschunterricht 5 (2), 1–21 (Original work published 2023).
DOI: 10.18716/OJS/MIDU/2023.2.5
Schindler, Kirsten/Wolfe, Joanna (2014): Beyond single authors: Organizational multi-authorship in collaborative writing. In: Jakobs, Eva-Maria/Perrin, Daniel (ed.): Handbook of writing and text production. Berlin: De Gruyter, 159–173.
Schneider, Hansjakob/Anskeit, Nadine (2017): Einsatz digitaler Schreibwerkzeuge. In: Becker-Mrotzek, Michael/Grabowski, Joachim/Steinhoff, Torsten (ed.): Forschungshandbuch empirische Schreibdidaktik. Münster: Waxmann, 283–298.
Searle, John R. (1975): A Taxonomy of Illocutionary Acts. In: Günderson, Keith (ed.): Language, Mind, and Knowledge: Minnesota Studies in the Philosophy of Science. 7th edition. Minneapolis: Minnesota UP, 344–369.
Ständige Wissenschaftliche Kommission (2024): Large Language Models und ihre Potenziale im Bildungssystem. Impulspapier der Ständigen Wissenschaftlichen Kommission der Kultusministerkonferenz. Bonn.
URL: https://www.swk-bildung.org/content/uploads/2024/02/SWK-2024-Impulspapier_LargeLanguageModels.pdf
Sturm, Afra (2022): Schreiben für Anfängerinnen und Anfänger. In: Franken, Anna Ulrich/Pertel, Eva (ed.): 12 Perspektiven auf den Deutschunterricht. Wissenswertes für Lehrkräfte. Jambus.
QUA-LiS NRW, 215–241.
URL: https://www.schulentwicklung.nrw.de/cms/jambus/handreichung/index.html
Weiqi, Tian/Jingshen, Ge/Yu, Zhao/Xu, Zheng (2024): AI Chatbots in Chinese higher eduaction: adoption, perception, and influence among graduate students – and integrated analysis utilizing UTAUT and ECM models. In: Frontiers in Psychology (15).
DOI: 10.3389/fpsyg.2024.1268549
Vodafone Stiftung (2023): Aufbruch ins Unbekannte. Schule in Zeiten von künstlicher Intelligenz und ChatGPT. Düsseldorf.
Weßels, Doris (2025): Schluss mit absurden KI-Regeln! In: DIE ZEIT (3).
URL: https://www.zeit.de/2025/03/kuenstliche-intelligenz-studium-hochschulen-regeln